



近年、私達の身の回りにはAIがあふれる時代となってきました。AIカメラ(物体識別)やAI翻訳機、AI囲碁・AI将棋、などなど…。それらは今や人間と同等か、それ以上の性能を発揮することもあります。皆さんは、これらのAIがどのような思考プロセスを経て結論を導き出しているか、気になったことはないでしょうか?はたして人間の頭の中と似たような思考を行っているのか、あるいは全く異なる考え方をしているのか――。
AIの急速的な普及とともに、AIの「信頼性」が重要視されるようになりました。前回のブログでは、Trustworthy AI(信頼できるAI)に求められる4つの要件として、Robustness (頑健性)、Explainability (説明可能性)、Fairness (公平性)、Privacy (プライバシー) の概要をご紹介しましたが、その中でも前述のような疑問に答えてくれるのがAIのExplainability (説明可能性)です。本稿では、AIのExplainability について詳しく解説します。
Explainability はAI が何らかの誤判定をしたときなどに「なぜそのような推論をしたのか」についての根拠を示す際に特に必要となります。あなたが提供している、もしくはしようとしている AI 活用サービスが AI の推論結果が原因で何らかの不利益をユーザに与えた場合、ユーザを含めた関係者に説明責任を果たすことは可能でしょうか?本稿が AI を活用したサービスを提供する方達にとって Explainablilty というものがどのようなものかを理解し、その必要性を考えるきっかけとなれば幸いです。
Explainable AI(説明可能なAI)とは
Explainability (説明可能性)とは、AIが導き出した答えについて、「なぜその答えを出したのか」が説明できる能力の高さのことを指し、この能力が高いAIのことをExplainable AI(説明可能なAI)と呼びます。たとえば、与えられた画像に何が写っているか(犬やカメラ、自転車など)を推論するAIがあった際に、画像の中のどんな特徴に注目してその結論を導き出したかを説明できるものを指します。犬の写真を見せたときに、あるAIは「耳や鼻、尻尾のような形が見えたので犬だと判断した」と説明するかもしれません(図1)。
AIの推論結果の根拠を説明でき、その説明が、人間が判断する基準に近い(納得感がある)ことが、人間の仕事を代替できる「信頼できるAI」の必要条件となると考えます。信頼できる AI とはあまり関係ありませんが、たとえばもしAI囲碁やAI将棋の頭の中を覗くことができれば、我々の考えも及ばない、人智を超えた新たな定石の発見につながるといったことも期待できるかもしれません。
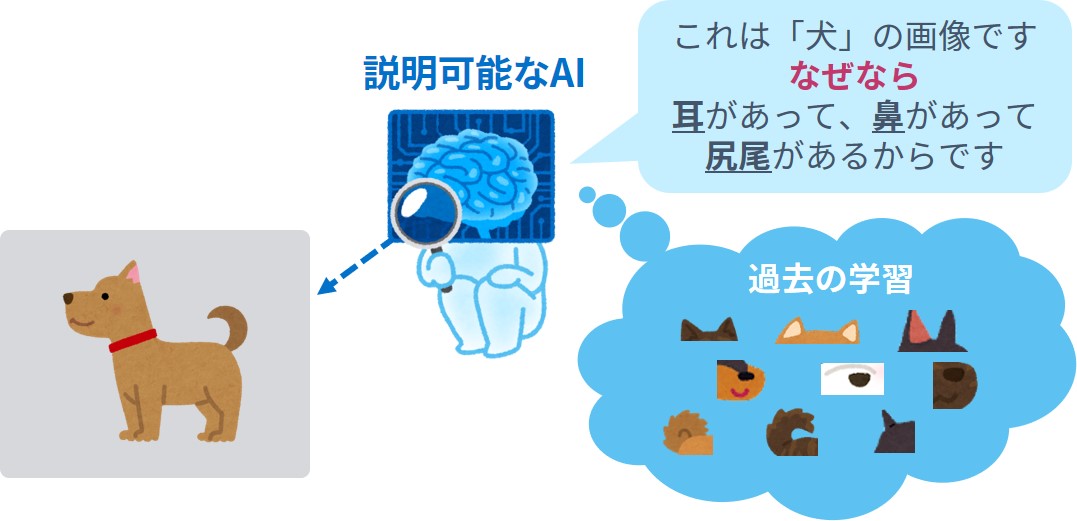
図1 犬の画像を認識するAI
いまExplainable AIが求められる理由
Explainable AIは、特に今後AIの活用が期待される医療業界や金融業界などで重要視されています。たとえば、AIが医師に代わって病気の診断をする際には、診断の根拠となる症状や症例を説明できる必要があります。逆に人の命に関わる可能性がある現場では、根拠を説明できないAIに、人間が安心して業務を委ねることは難しいでしょう。Explainable AIはすでに実用化が始まっており、Alpha Goで有名なGoogle子会社のDeepMind社は、2018年、眼内のCT画像から網膜疾患の診断を高い精度の根拠を持って実現するシステムを開発しました(図2)。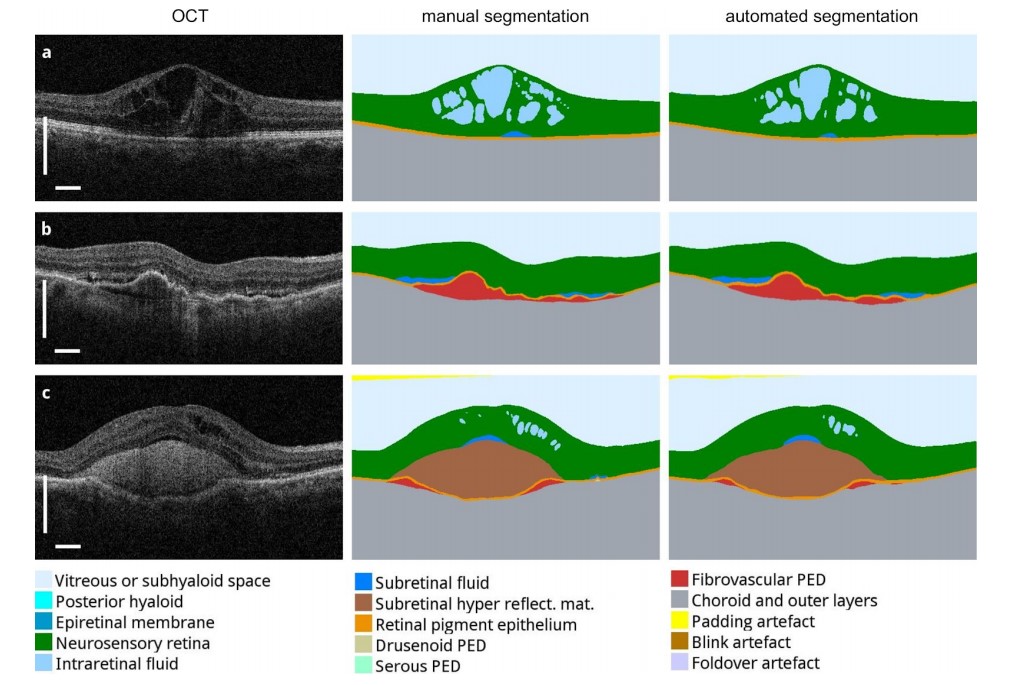
図2 眼内のCT画像(左)とAIの説明(中・右)。赤く色付けされた部分が疾患のある箇所であることを表している。
De Fauw et al. "Clinically applicable deep learning for diagnosis and referral in retinal disease".
https://www.nature.com/articles/s41591-018-0107-6
Explainable AIの注目度がここ数年で急速に高まっている背景には、ディープラーニング技術の台頭が大きく関わっています。ディープラーニングの活用によって、多くのAIの推論精度は格段に向上しました。一方で、複雑なニューラルネットワークによって構成されるモデルの特性上、従来の機械学習手法に比べて内部のロジックがブラックボックスであり、推論の過程を説明しにくいという問題があります。そこで近年ではディープラーニングを中心とした機械学習手法に適用可能なExplainability AI関連についての手法が活発に研究され、ここ数年で多くの論文が発表されています(図3)。
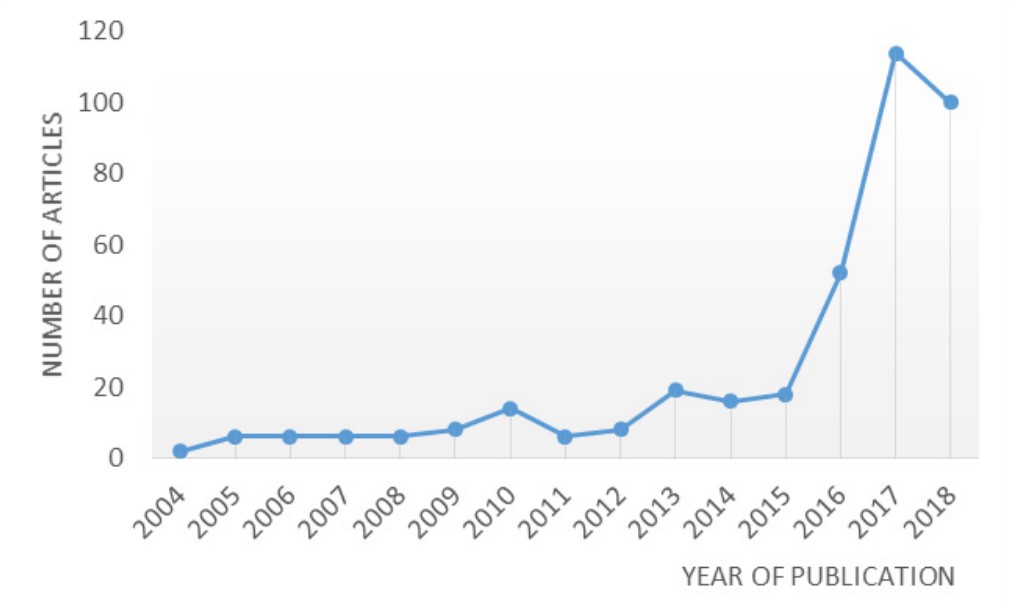
図3 Explainable AI 関連の論文発表数の推移
Amina Adadi and Mohammed Berrada, “Peeking Inside the Black-Box: A Survey on Explainable Artificial Intelligence (XAI)”,
https://ieeexplore.ieee.org/document/8466590
本稿では、中でも著名な手法である、Integrated Gradients(以降、「IG」と表記)、Local Interpretable Model-agnostic Explanations(以降、「LIME」と表記)、SHapley Additive exPlanations (以降、「SHAP」と表記)とよばれる手法を解説します。加えて、Explainable AIのための手法に誤った説明を出力させるように誘導させる攻撃手法について解説します。
Explainable AIの手法
推論結果を説明する手法は前提条件によって二つに大別されます。一つはモデルの構成が既知であるホワイトボックスの手法と、もう一つはモデルの構成情報を必要としないブラックボックスの手法です。本章ではホワイトボックスの手法であるIGと、ブラックボックスの手法であるLIME、SHAPについて、それぞれ適用例を紹介しながら、簡単な解説を行っていきます。
Integrated Gradients
まずはIGによる推論結果の説明を見てみましょう。この手法は下記の論文で紹介されています。
―Mukund Sundararajan, Ankur Taly, Qiqi Yan, "Axiomatic Attribution for Deep Networks", https://arxiv.org/abs/1703.01365―
一つ目の例は画像分類に関する説明結果です (図4)。最左列が入力となるオリジナルの画像、左から二列目が画像の推論結果、そして、三列目はIGによる説明結果を表しています。例えば、左上のカメラの画像にIGを適用した結果を見てみると、推論結果はreflex camera(レフレックスカメラ) で、スコア (確率のように解釈されるもので、1が上限)は0.99375となり、かなりカメラの可能性が高いという結果になっています。実際にIGによる推論結果の説明を見てみると、カメラのボディやレンズの輪郭部分が強調されており、AIがどの部分をベースに判断したのかがわかりやすく図示されています。
図4 IGによる入力画像の説明
入力画像(左) 分類結果とスコア(中央) IGによる入力画像の説明(右)
―Mukund Sundararajan, Ankur Taly, Qiqi Yan, "Axiomatic Attribution for Deep Networks", https://arxiv.org/abs/1703.01365 ― より一部抜粋
二つ目の例は疑問文のテキストが入力として与えられ、その質問がどのような種類に分類されるかを推論するというタスクに関する説明結果です(図5)。Predictionと書かれている部分が推論結果です。例えば、1番上の文章を見ると、問われているのは数値(NUMERIC)である、という推論をしており、その根拠として実際に数値を尋ねる疑問詞の「how many」がIGの説明によって赤色で強調されています。

図5 疑問文の推論タスクにおけるIGによる説明
―Mukund Sundararajan, Ankur Taly, Qiqi Yan, "Axiomatic Attribution for Deep Networks", https://arxiv.org/abs/1703.01365 ― より一部抜粋
では、IGでは一体どのような考えに基づいて上記のような説明結果を出力しているのでしょうか。原理を理解するためには「ベースライン」と「勾配」という概念の理解が必要になります。今回は画像分類を例にとって簡単に解説をします。
ベースラインとは該当のスコアが0(厳密には0に近い値)になるような画像(多くの場合、黒塗りの画像)です。このベースライン画像を出発点として、スコアが約1となる入力画像に徐々に近づけていきます。勾配とは、ある画像が入力として与えられた時、その画像のスコアを効率的に大きくするために画像をどのように変化させればよいか、という情報です。IGはモデル構造が既知であることを前提としており、分類スコアを入力画像に関して微分することによって勾配を求めることができます。
以上を念頭に置きながら、IGで実際にどのような計算をしているかを表したものが図6です。ベースラインを徐々に説明したい入力画像に近づけながら、スコアに対する勾配情報を計算して平均をとり、値(貢献度)が大きいピクセルを強調して表示させています。ベースラインから入力画像までの各ポイントにおける勾配情報を加味しつつIGの値を計算しているため、説明対象の画像において、スコアが0から1に近い値になった理由を表現することができる、と考えることができます。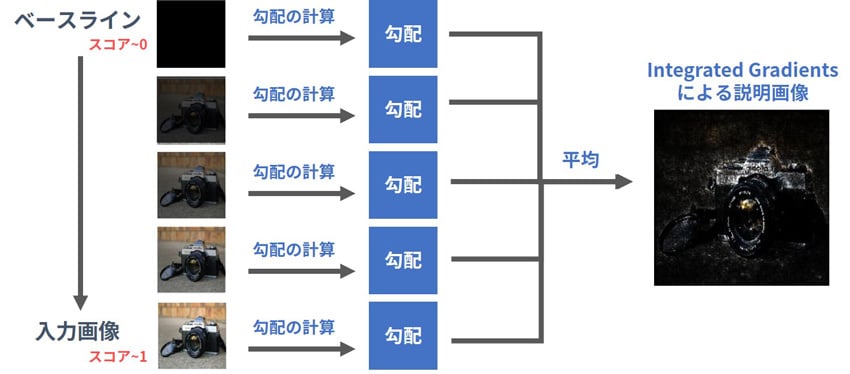
図6 IGの処理
LIME
続いてはLIMEについて見てきます。この手法は下記の論文で紹介されています。
―Marco Tulio Ribeiro, Sameer Singh, Carlos Guestrin, ""Why Should I Trust You?": Explaining the Predictions of Any Classifier", https://arxiv.org/abs/1602.04938―
LIMEによる画像分類の説明を二例紹介します。一つ目は画像の分類結果として、複数の候補が出力された場合の説明です(図7)。一番左の画像(a)の分類結果として、スコアの高い順に「エレキギター」、「アコースティックギター」、「ラブラトールレトリーバー」があげられています。左から二~四枚目の各画像は、それぞれの推論結果について、入力画像のどの部分が推論に強く貢献しているかを表しています。画像を参照すると、(b)ではギターのネック部分、(c)ではギターのボディ部分、(d)ではラブラドールレトリーバーの顔部分が出力されており、このAIは納得感のある根拠をもとに推論できていそうだと判断することができます。先程のIGのカメラの例とは異なり、ピクセル単位ではなく、切り絵のように特定の領域を強調している点がLIMEの特徴です。

図7 LIMEによる各分類スコアに対する入力画像の説明
―Marco Tulio Ribeiro, Sameer Singh, Carlos Guestrin, ""Why Should I Trust You?": Explaining the Predictions of Any Classifier",
https://arxiv.org/abs/1602.04938―より抜粋
二つ目の例は、入力画像を「ハスキー」と「オオカミ」のどちらかに分類するタスクにおけるLIMEの説明です(図8)。左の画像は実際にはハスキーですが、AIによるとオオカミと分類されています。LIMEによる説明画像が右側の画像になります。この説明画像から読み取れることは、オオカミと分類した根拠は背景の雪の部分である、ということになります。本来であれば目や耳、鼻、口などのオオカミそのものの特徴を根拠に推論すべきと考えられますが、背景画像をもとに分析してしまっていることがわかります。AIの推論の過程は必ずしも人間の感覚と同じものではないという興味深い事例の一つです。
図8 不適切な分類モデルにおける入力画像に対するLIMEの説明
―Marco Tulio Ribeiro, Sameer Singh, Carlos Guestrin, ""Why Should I Trust You?": Explaining the Predictions of Any Classifier",
https://arxiv.org/abs/1602.04938―より抜粋
では、LIMEでは一体どのようにしてこのような説明画像を生成するのでしょうか。その鍵は「解釈が容易なモデルでの局所的な近似」にあります。この概念を説明したものが図9です。一般にAIのモデルは、分類の境界線(図9における赤と青の境界線)が非常に複雑な形をしており、人間の知覚には解釈しにくいものになっています。一方、入力画像(赤い+印)とその周辺のデータ(緑色の領域)だけに着目すると、点線で表された直線(シンプルなモデル)を用いることでも一定レベルの分類が可能であることがわかります。LIMEではこのような局所的なデータを分類するためのシンプルで解釈可能なモデルを説明対象のモデルとは別途求めることをゴールとしています。
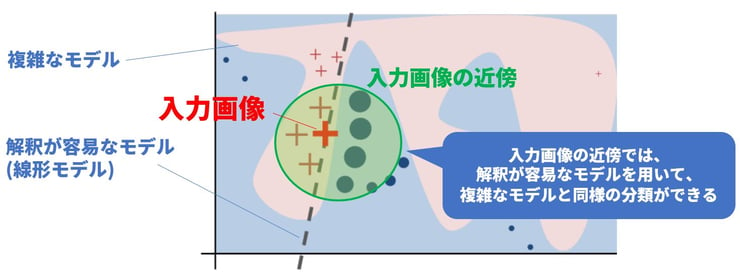
図9 LIME概念図
―Marco Tulio Ribeiro, Sameer Singh, Carlos Guestrin, ""Why Should I Trust You?": Explaining the Predictions of Any Classifier",
https://arxiv.org/abs/1602.04938―より抜粋し、説明を追加
LIMEのより具体的な手続きについて解説します(図10)。まず、入力を人間が解釈しやすいような特徴量に分割します。例えば、LIMEの一つ目の画像の例で考えると、図のように入力画像を大雑把に分割します(実際には、例のようにシンプルにマトリクスに分割するのではなく、色合いや距離的に近い部分で塊をつくります)。分割した画像から、ランダムに歯抜けになった画像を作成し、通常の推論を行い各スコアの算出を行います。この歯抜け画像とスコアのペアを大量に作成し、これらの情報をもとに解釈が容易なモデル(例えば、線形モデル)で近似します。この手続の中では、もとの複雑なモデルの構成情報を必要としません。
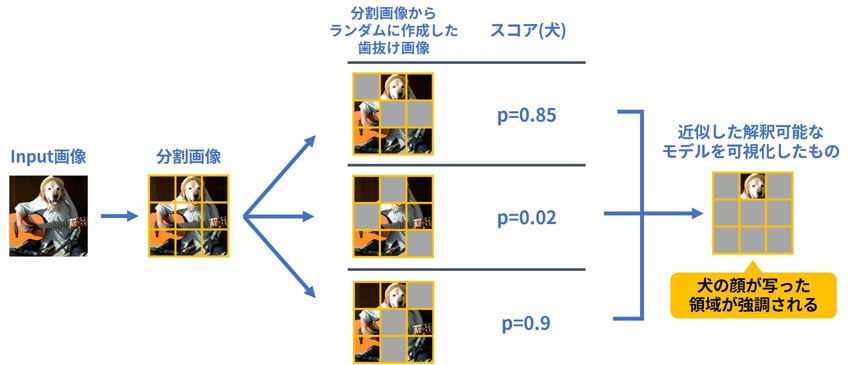
図10 LIMEの処理
例えば解釈可能なモデルとして、線形モデルで近似した場合、関数の各係数の大きさを各塊の重要度とみなせるため、出力結果が人目で確認してわかりやすいものになります。ただし、生成プロセスからわかるように、この説明はもとのモデルにおける特定の入力と出力のペアに対してのみ対応することになり、ほかの分類結果の説明としては適用できません。これが、本手法が局所的な近似と呼ばれる理由です。
SHAP
次に、SHAPについて解説します。この手法は下記の論文で紹介されています。
―Scott Lundberg, Su-In Lee, "A Unified Approach to Interpreting Model Predictions", https://arxiv.org/abs/1705.07874―
SHAPは、協力ゲーム理論における「Shapley値」とよばれる考え方を応用しており、SHAPを理解するためには、Shapley値についての理解が必要不可欠です。Shapley値は、ゲームにおける報酬を参加プレイヤーに公平に分配する場合などに利用されます。まずは、「アルバイトゲーム」という例を用いて、Shapley値について説明します。
アルバイトゲームとShapley値
A君、B君、C君の三人がアルバイトをします。アルバイトは一人で行ってもよいし、協力して二人、三人で行っても問題ありません。各パターンでアルバイトをした時の合計の報酬は表1の通りです。例えば、A君一人で参加した場合は6万円、三人で参加した場合は合計で24万円の報酬がもらえます。
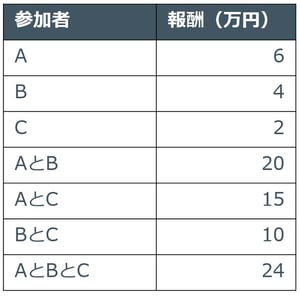
表1 アルバイト実施時の報酬
数値例は岡田 章 “ゲーム理論 新版“のものを利用
この時、三人全員でアルバイトを行ったときの報酬24万をどのような考え方で三人に分配すればよいでしょうか。単純に8万ずつ分けるという考え方もできますが、貢献度の高い人にはたくさんの報酬を与えたほうが公平です。そこで、各人について、その人が参加した際の報酬の上げ幅(これを「限界貢献度」と呼びます)を考えてみます。例えば、A君が参加した場合は表2のようになります。
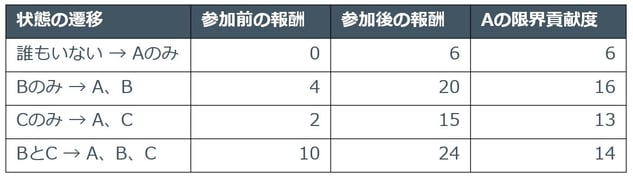
表2 A君の限界貢献度
次に、参加順の効果を打ち消すため、限界貢献度の平均をとります。今回は三人のため、すべての参加順序を考えると6通りになります。こうして計算した平均的な限界貢献度のことをShapley値と呼び、これらが実際に各人に支払われる報酬額になります(表3)。 8万円ずつ均等に分配するよりは、各人の貢献度を考慮した分配になっているため、公平性があるといえるのではないでしょうか。
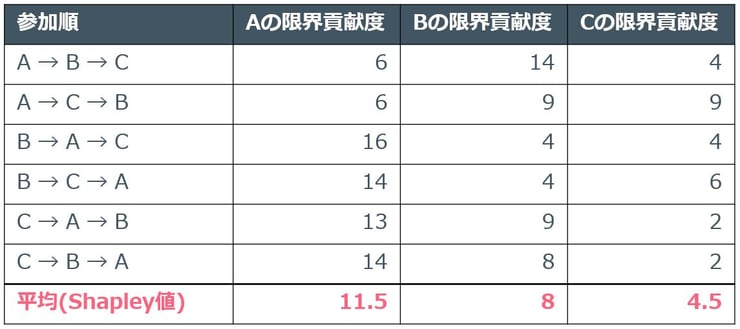
表3 各参加順における各人の限界貢献度とShapley値
SHAPへの応用
SHAPではShapley値における「ゲームの各プレイヤー」を「機械学習における特徴量」として、「分配された報酬」を「貢献度」として見たてて考えています。しかし、機械学習においては「あるプレイヤーがいないとき」の報酬のような、「ある特徴量がないとき」の推論を求めることは困難です。そこで、「平均的な推論」をベースに、ある特徴量が加わったときの推論の変動量をその特徴量の限界貢献度(貢献度の上げ幅)の期待値として考えることで代替します。この期待値の計算方法はいくつか考えられており、さまざまな学習モデルについてSHAPを効率的に計算するアルゴリズムが提案されています。
ここで、機械学習の分野で広く用いられているBoston housing(ボストンの住宅価格)のデータセットを利用した回帰タスクにSHAPを適用した例を紹介します。このタスクでは、犯罪率や環境、部屋数などといったその土地の特徴をもとに、住居価格を推論します。とある入力の各特徴量の値と、それをもとにAIが推論した住居価格を表4に示します。

表4 Boston housingの入力データと住居価格の推論
lib.stat.cmu.edu/datasets/boston より引用
このタスクにSHAPを適用した結果が図11です。このデータセットに対する平均的な予測値はE[f(X)]=22.533であり、今回の入力の予測値はf(x)=24.019となりました。図では、予測値がE[f(x)]からf(x)に至るまでに、どの特徴量が推論に対してどの方向にどれだけ作用したかを表しており、矢印の長さが長いほどその特徴量の影響が大きいと言えます。この入力データでは平均と比べると推論が約1.5弱程高くなっていますが、その一番の要因はLSTAT(低所得者の割合)であることがわかります。実際、今回の入力データにおけるLSTATの値は4.98(データセットの平均値は8.8647)と、平均と比べて低くなっており、「低所得者の割合が低い地域の住居価格は平均よりも高くなる」という私達の感覚とも近いことがわかります。
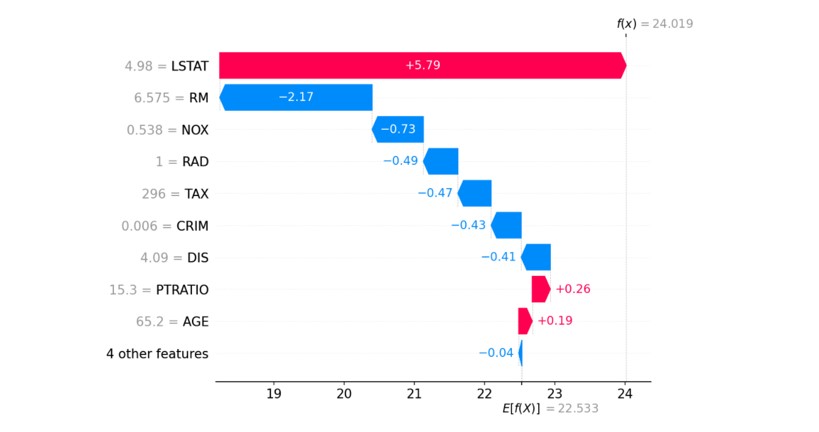
図11 SHAPによる住居価格の予測値の説明
https://github.com/slundberg/shap
Explainable AIに対する攻撃
Explainable AIに関する手法が盛り上がりを見せる中、誤った説明に誘導させる攻撃手法が発表されました。
Ann-Kathrin Dombrowski, Maximilian Alber, Christopher J. Anders, Marcel Ackermann, Klaus-Robert Müller, Pan Kessel, "Explanations can be manipulated and geometry is to blame", https://arxiv.org/abs/1906.07983
まずは図12の画像をご覧ください。左上がオリジナルの画像、右上はオリジナル画像に細工を施した画像です。下段はそれぞれの画像に対して、IGのような説明可能なAIの手法を適用した結果です。上段の2つの画像は人間の目には違いがわからないにも関わらず、説明画像が大きく異なることが見て取れます。本来は犬の画像に対して、目や鼻、耳の部分が強調されるはずですが、この攻撃手法の適用後は「this explanation was manipulated(この説明は操作された)」という攻撃者のメッセージが表示されています。この論文では、オリジナルの画像と細工した画像が近い状態を維持しつつ、同時に説明画像を攻撃者が用意したものに近づけるという最適化問題を解く手法が提案されています。

図12 画像の説明に対する攻撃
Ann-Kathrin Dombrowski, Maximilian Alber, Christopher J. Anders, Marcel Ackermann, Klaus-Robert Müller, Pan Kessel, "Explanations can be manipulated and geometry is to blame", https://arxiv.org/abs/1906.07983 より抜粋した画像に説明を追加
このような手法を悪用した場合、例えば、何らかの説明機能のついたAI製品があったとき、それにでたらめな説明をさせることで、その推論結果の根拠調査を混乱させたり、その製品の信頼を失墜させたりできるといった脅威が想定されます。
論文中では、AI開発者があらかじめモデルのパラメータを適切にチューニングしておくことで本攻撃を防ぐことができるとされています。このように、Explainable AIが正常に機能しており、攻撃者の手が加わった恣意的な結果が表示されていないかといったことについても考えていく必要があると言えます。
まとめ
本稿では、Explainable AI(説明可能なAI)とはなにか、またそれに用いられる手法と、Explainable AIを欺く攻撃手法についてご紹介しました。本稿の中ではできるだけ数式を用いず、概要を噛み砕いてご説明しましたが、論文を読み解くことで、これらの手法が数学的な理論に裏打ちされた、緻密なシステムであることがわかります。
我々NRIセキュアの「Trustworthy AI 研究チーム」では、これらの手法の調査・実装・評価などを行い、将来の事業につなげる取り組みを行っています。私達のセキュリティ業界においても、AIの活用は必要不可欠なものとなりつつあります。AIが搭載されたアンチウイルス製品がとあるファイルを悪性として検出したときに、悪性と判断した理由を説明できない製品を信頼できるでしょうか?SOCのようなセキュリティログ監視をAIが行う際に、アラートの発生原因を尋ねると「AIがそう判断したから」とだけ返されてしまうサービスを信頼できるでしょうか?
AIはそれ単体であらゆる課題を解決する「銀の弾丸」ではありません。AIは人間の仕事を代替してくれますが、あくまでAIを使いこなすのは人間であり、AIの出す結論が信頼に足るものなのか最終的に判断し、そこに責任を持つのも人間です。その判断材料として、AIによる説明は非常に重要となってきます。今後は、AIが高い精度の推論ができるのは当たり前、推論根拠にどれだけの説得力を持つことができるか、という点が AI ないしはそれを利用するサービスの信頼性を高め、結果として差別化ポイントとなっていくことでしょう。
本シリーズでは、Explainable AIの他にも、様々なTrustworthy AI(信頼できるAI)についてご紹介していますので、ぜひご覧ください。
- 本ブログの執筆者が所属する研究チーム紹介ページはこちら!
- 「Trustworthy AI 研究チーム」紹介ページ




















