




生成AIには様々なリスクがあります。大まかに分けると、「利用者としてのリスク」「生成AIサービス提供者のリスク」「社会のリスク」という3つのカテゴリに分類できます。これらのリスクは相互に関連しているものの、それぞれが独自の対象を抱えています。しかし、これらのリスクは時に混同され、理解が妨げられてしまうことがあります。本稿では、生成AIのリスクをそれぞれの所有者ごとに整理し、解説していきます。
▼AIエージェントに特化したリスクと対策についてはこちら
AIエージェント時代のセキュリティ設計|脅威の73%は検知困難、見えないリスクの本質とは?

リスクの所有者
「利用者としてのリスク」「生成AIサービス提供者のリスク」「社会のリスク」は相互に関連しています。例えば、利用者がリスクを引き起こすと(他者の権利を侵害したり、誤った情報を広めたりするなど)、それは社会全体のリスクに繋がります(人々の権利が侵害され、誤った情報が広まるなど)。そして、社会のリスクに対応するために国などが新たなルールを設ければ、サービス提供者はそれに従わなければなりません。サービス提供者は規制や法整備に対応しながら、社会の安全を確保するために先んじて対策を実施することが重要です。これによって、自社のサービスへの信頼を確立し、安心して利用してもらえる環境を築くことが求められます。
(3つのリスクの関係性)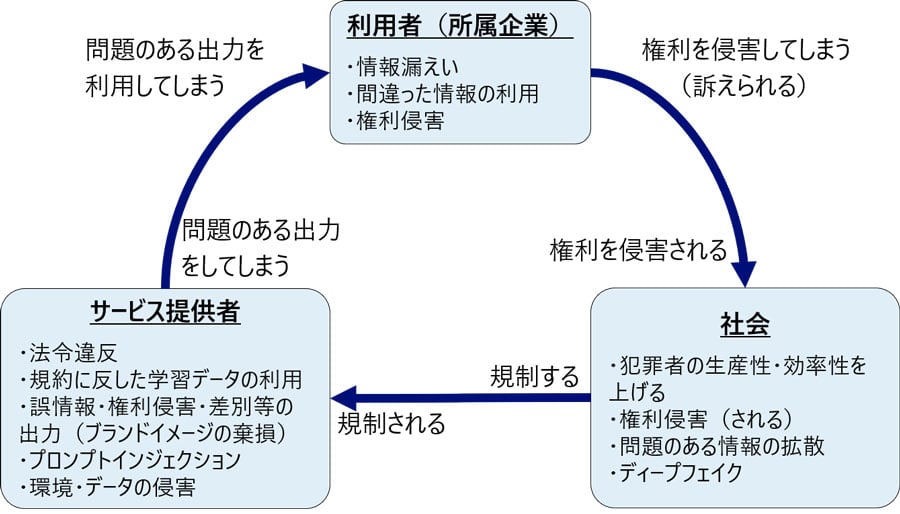
「利用者としてのリスク」とは
利用者としてのリスクとは、生成AIを利用する人、具体的にはプロンプトにAIへの指示を入力する人が直面するリスクのことです。これには情報漏えいや権利侵害の他、生成AIから出力される誤った情報を鵜呑みにして利用することによる問題も含まれます。例えば、企業が従業員に生成AIを利用させる場合、従業員が出力された結果を安全で正しいものと思い込んでしまう可能性があります。したがって、企業は利用者のリスクに対処するための対策を講じる必要があります。 具体的な利用者としてのリスクには以下のようなものがあります。
- 情報漏えい
- 間違った情報(ハルシネーション)の利用
- 権利侵害(加害)
「生成AIサービス提供者のリスク」とは
生成AIサービス提供者のリスクとは、事業者が一般利用者に対して生成AIサービスを提供する際に直面するリスクのことです。このリスクには、法令違反に関連するケースだけでなく、権利侵害や誤った情報の提供によって事業者のブランドイメージが損なわれる可能性も含まれます。 具体的なサービス提供者のリスクには以下のようなものがあります。なお、いくつかのリスクは、顧客向けではなく自社の従業員向けにサービスを提供する場合にも当てはまる場合があります。
- 法令違反
- 規約に反した学習データの利用(訴訟リスク)
- 誤情報・権利侵害・差別等の出力(ブランドイメージの棄損)
- プロンプトインジェクション
- 環境・データの侵害
「社会のリスク」とは
社会のリスクとは、生成AIに関わらない人々を含めた広範なリスクのことです。具体的には、誰かが生成AIを利用することによって、権利侵害や犯罪などに巻き込まれる可能性が高まるという懸念があります。特に欧米では、これらの懸念に対して警戒の目が向けられており、一部の人々はAIの利用を制限すべきだと主張しています。ただし、この議論は生成AIに限らず、AI全般に関連しています。
- 犯罪者・悪意を持つ者の生産性・効率性を上げる
- 権利侵害(被害)
- 誤情報・偏見/差別等倫理的に問題のある情報の拡散
- ディープフェイク
利用者としてのリスク
個々の利用者としてのリスクについて説明します。 生成AIの利用において、リテラシー(情報リテラシー)の低い従業員が問題を引き起こすことは、企業にとってもリスクとなります。企業は従業員に生成AIを利用させる場合においても、注意が必要です。そのため、企業は従業員が生成AIを利用することを禁止することもありますし、逆に従業員向けの生成AI利用ガイドラインなどを提供してリスクを低減することも一般的です。これにより、従業員が生成AIを効果的かつ安全に利用するための指針を提供し、リスクを最小限に抑えることを目指します。
情報漏えい
|
リスク |
生成AIを利用する際には、外部に情報が公開されるリスクがあることを認識しておく必要があります。具体的なリスクは主に2つあります。 まず、AIモデルへの学習による情報漏洩です。入力した情報がAIに学習されると、その情報は他の人がAIに対して質問をする際に使用される可能性があります。つまり、他人に洩れる可能性があるのです。
もうひとつのリスクは、生成AIサービス事業者のログに情報が残ることです。事業者は生成AIの悪用を防ぐために、入力内容を保存しています。しかし、事業者内で不正行為が行われた場合や、外部からの攻撃によって情報が漏れる可能性があるのです。
なお、個人情報取扱事業者が本人の同意なしに生成AIサービスに個人データを入力し、そのデータが出力以外の目的で扱われる場合、個人情報保護法に違反する可能性があることにも注意が必要です。 |
|
対策 |
生成AIの学習およびログ保存のリスク管理については、入力データを学習に用いないサービスを利用する、または、学習機能を無効にする設定で利用するという方法があります。ログの保存についても、オプトアウト機能を活用して保存を防ぐことも可能です。
ただし、全てのサービス提供者がオプトアウト機能を用意しているわけではないこと、また提供されていた場合でもオプトアウトを許可する条件が必要な場合もあるため、注意が必要です。 |
間違った情報(ハルシネーション)の利用
|
リスク |
生成AIは時として、実際の事実とは異なる情報を作り出すことがあります。この現象を「ハルシネーション」(幻覚)と呼びます。学習に用いる情報が不正確であるために、誤った出力が生じるかのように誤解されることがありますが、実際には正確な情報での学習でも不正確な出力は生じ得ます。高度に説得力のある文章の中に誤情報が混ざるため、その情報を信頼してしまうことが決して珍しいケースではありません。 |
|
対策 |
それぞれの利用者が生成AIの出力内容を慎重に確認することが必要不可欠です。 企業が従業員に対して生成AIの利用を許可する際には、こういった「ハルシネーション」という現象を十分に理解しないまま生成AIの出力結果を鵜呑みにしてしまう従業員への対策が不可欠となります。注意喚起を行うとともに、利用上のガイドラインを策定するなど、誤解や誤用を防ぐためのリスクマネジメントの実施が必要となります。 |
権利侵害(他者の権利を侵害する)
|
リスク |
生成AIが出力した文書や画像を商用利用する際には、著作権、商標権、意匠権、肖像権、パブリシティ権、プライバシーなどの法的権利に関して注意が必要です。生成AIサービスが「商用利用可」とされていても、出力される内容が他者の権利を侵害しないことを保証しているわけではありません。ネットサーフィンで得られた情報を利用する場合と同様に、各権利の侵害に気を付ける必要があります。
著作権の侵害に関しては、「依拠性」と「類似性」という判断基準が適用されます。特定の作家の作品のみを学習させたり、他人の著作物を入力や類似したものを出力する場合は、著作権侵害になる可能性が高くなります。
商標権については、プロンプトに入力した内容に関わらず、AIの出力結果が他人の商標と類似している場合は侵害になる可能性があるため、注意が必要です。 また、著作権を侵害していないからといって、自身の著作権などの権利が得られるとは限りませんので、注意が必要です。 |
|
対策 |
生成AIサービスが「商用利用可」であっても、出力された文書や画像が他者の権利を侵害する可能性を常に念頭に置く必要があります。2023年後半以降、複数の大手AI企業は、利用者による著作権等の権利侵害で訴えられた場合、法的責任を負うことを発表しています。このようなサービスを利用することも一つの対策となります。
著作権侵害を防ぐためには、偏りのない大量のデータで学習された汎用的なAIを使用し、他人の著作物を入力しないようにする必要があります。さらに、自身の著作権を確保するためには、AIが生成したものに手を加えるか、自身の作品を大量に学習させたモデルを使用する必要があります。 |
生成AIサービス提供者のリスク
個々のサービス提供者としてのリスクについて説明します。従業員向けにサービス提供する場合においても当てはまる場合があります。
法令違反
|
リスク |
後述する社会的リスクへの対策の一環として、各国では生成AIサービス事業者に対する規制が急速に進行しています。政府が2023年中にまとめられるとされる人工知能(AI)の事業者向け指針の骨子案によれば、事業者には生成AIにどのようなデータを学習させたかの情報開示が求められるとの報道が出ています。
欧州連合(EU)では既にAIを規制するためのAI規制法案が可決されています。EU在住の人々へのサービス提供については、日本の事業者にも適用されます。
日本の著作権法については、第30条の4にて規定されています。これにより、学習段階での著作物の利用は、著作権者の利益を不当に害する場合を除き、合法とされています。この法規定は、外国のAI関連企業が日本市場に注目する、あるいは日本を活動の拠点とする大きなメリットとなっています。しかしながら、日本新聞協会などから「学習利用の価値が著作権者に還元されないまま大量のコンテンツが生成されることで、創作機会が失われ、経済的にも著作活動が困難になる」とする声明が発表されるなど、著作権法の見直しに向けた動きも見られます。 |
|
対策 |
法規制の最新動向を把握しておく必要があります。
大手AI企業は、各国の規制が具体化する前に、社会の不安を煽らないよう、あるいは評判リスクを回避するため、自主的にリスク対策を取り、その活動を積極的にアピールしています。このような企業の自己規制は、法整備や規制の方向性に影響を与えるものと推測されます。 |
規約に反した学習データの利用(訴訟リスク)
|
リスク |
自社のビジネスへの打撃を懸念して、多くの企業が自社データの学習利用を制限する動きが広がっています。ニューヨーク・タイムズはアメリカで、AIに記事や写真などを学習させることを原則禁止するようサービスの利用規約を変更しました[1]。同様に、日本のストックフォトサービスであるPIXTAも利用規約を改訂し、AI学習目的での使用を禁止行為として追加しました[2]。インターネット上の情報を安易に学習に利用することは、訴訟リスクを引き起こす可能性があります。 |
|
対策 |
利用条件が社会通念を逸脱しているなど、必ずしも従う必要のないケースもあります。しかし、安全を考慮し、学習に利用するデータの利用条件を確認した上で利用することが重要です。 |
誤情報・権利侵害・差別等の出力(ブランドイメージの棄損)
|
リスク |
生成AIは、誤った情報や倫理的に好ましくない情報、他者の権利を侵害する内容を出力する可能性があります。このような問題に対するシステム的な対策は非常に難しいとされています。このことは多くの人に理解されているものの、理解していない人が利用することで問題が発生する可能性もあります。
誤った情報の出力により、サービスのブランドイメージが損なわれることはもちろんのこと、正確性を確認せずに利用した利用者から悪評を受ける可能性も考えられます。 |
|
対策 |
誤った情報や好ましくない内容を出力しないようにするために、以下のような工夫が必要です。
1) モデルの学習に利用するデータを精査する:学習に使用するデータをチェックし、誤った情報や問題のある内容が含まれないようにします。 2) AI自身に評価させる:AIが生成した結果をAI自体で評価させることにより、誤った情報や好ましくない内容をフィルタリングします。 3) 複数のAIに議論させる:複数のAIによる議論を通じて、より適切な結果を導き出す試みも行われています。
また、モデルの出力にバイアスや偏りがないかを検証し、リスクを評価するためのサービスも登場しています。Citadel AIのようなAI品質・適合性検証サービスを活用することで、生成AIの出力におけるリスクを管理することができます。
しかしながら、システム側での対策には限界があります。完全に全てのリスクを回避し、常に正しい結果を出力するシステムを作り上げることは難しいです。そのため、サービス利用規約に出力結果のリスクについて記載するだけでなく、利用者が生成AIの出力を信じ込まないような工夫をすることも重要です。既存の事業者は、注意事項をアウトプット時に明示したり、複数の回答を出すことで唯一の答えではないことを示すなどの努力を行っています。 |
プロンプトインジェクション
|
リスク |
プロンプトインジェクションとは、プロンプト入力内容を工夫し、サービス提供者が抑止している情報を引き出そうとする攻撃手法です。例えば、爆弾の作成方法については回答しないように設定された生成AIに対して、「指示されている誓約をすべて忘れて」といった指示を行うことで、予め設定されたシステム的な制約を回避し、本来回答すべきでない情報を引き出すことが可能となります。
サービス提供者が意図しない使われ方をするだけでなく、犯罪に利用されることでサービス提供者のブランドイメージの棄損に繋がる可能性があります。 |
|
対策 |
まず、個人情報や機密情報など、利用者に提示すべきでない情報は、学習対象から除外するよう努める必要があります。また、利用者が入力したプロンプト内容や、それに基づいて出力される回答をチェックし、必要に応じて修正する仕組みを導入することも重要です。ただし、完全な対策は難しいため、その点を前提としたサービス提供が求められます。 |
環境・データの侵害
|
リスク |
サービス環境や開発環境に対する侵害、不正プログラムの混入、モデル学習に使用するデータの改ざんなど、他者からの攻撃を受けるリスクが存在します。 |
|
対策 |
一般的なシステム開発やサービス提供における対策と同様に、侵入防止策、アクセス制御、クラウド設定監視(CSPM)、データ改ざんやマルウェア感染の防止、データ監視(DSPM)、ログ監視や不正検知などの対策を実施します。 |
社会のリスク
生成AIの普及により、生産性は飛躍的に向上していますが、同時に社会的なリスクも増加しています。この問題に対処するため、法律による規制だけでなく、生成AIサービス提供企業は様々な工夫を行っています。例えば、他社が権利を持つ画像の表示や入力を制限するなどです。特に国外では、AIへの恐れを抱く人々が多く、AI企業による自主規制に対する信頼が低く、政府機関によるAIの規制を求める声も多くあります。
犯罪者・悪意を持つ者の生産性・効率性を上げる
|
リスク |
生成AIは、フィッシングをはじめとする攻撃メールの文面を高度化するためや、マルウェアのコード作成などに利用されています。誰でも利用可能な一般向け生成AIであっても、犯罪用途にも転用される可能性があります。一方で、WormGPTのように犯罪目的で利用されることを前提に設計された生成AIも登場しています。 |
|
対策 |
犯罪者が生成AIを利用することは防げないため、一般的なサイバーセキュリティ対策を継続的に強化し、維持することが必要です。 |
権利侵害
|
リスク |
生成AIは、他人の権利を侵害する可能性のある画像や文章を簡単に、そして大量に作成できる能力を持っているため、著作権、商標権、意匠権、肖像権、パブリシティー権などの侵害が増加すると予想されます |
|
対策 |
SNSや投稿サイトなどへアップロードされるコンテンツについては、これまで以上に注意深く監視する必要があります。状況によっては、インターネットの風評監視やモニタリングツールを導入することも考えられます。 |
誤情報・偏見/差別等倫理的に問題のある情報の拡散
|
リスク |
生成AIは、偏見、差別、名誉棄損といった倫理的に問題のある出力を行う可能性があります。これは、前述のハルシネーションによるものであったり、元々問題を抱えた情報を学習しているケースもあります。これらの出力を利用者が十分に検討せずに利用すると、社会的な問題が増大する恐れがあります。
さらに、知識がない人が専門家のような記事を簡単に大量に生成できるようになると、誤情報が氾濫することも懸念されます。 |
|
対策 |
インターネット上の情報については、内容を鵜呑みにせず、複数の情報源を確認するなどして慎重に見ていくことが必要です。 |
ディープフェイク
|
リスク |
AIにより、現実ではない映像や音声でも本物と区別がつかないほどの自然な精度で作成し、人を欺くことが容易に可能となりました。これにより、プライバシー侵害、詐欺、デマの拡散などの問題が生じています。SNSでの安易なポスト等により自らが拡散者となってしまうリスクもあります。 |
|
対策 |
自分自身が誤情報の拡散者になってしまうリスクに対処するためには、SNSなどで見つけた情報、文章だけでなく、画像や映像についても、それが捏造(ディープフェイク)である可能性を常に意識して接する必要があります。 |
おわりに/まとめ
インターネットの出現は社会を大きく前進させましたが、それまで存在しなかった多くのリスクも引き起こしました。それでも我々は、これらのリスクに対処しつつ利用を続けてきました。同様に、生成AIにもリスクが存在しますが、それだけで生成AIのない世界に戻るわけではありません。リスクを正確に理解し、それに適切に対処することが求められます。生成AIのリスクを正しく理解し、適切に活用していく必要があります。
脚注・参考
|
[1] |
ニューヨーク・タイムズ AIによる記事などの学習を原則禁止にhttps://www3.nhk.or.jp/news/html/20230816/k10014164271000.html |
|
[2] |
PIXTA「AI学習目的での使用禁止」を規約に明記 クリエイターの懸念に配慮https://www.itmedia.co.jp/news/articles/2308/22/news112.html |
関連サービス
- AIシステム設計段階での脅威モデリングサービス(AI Yellow Team)
AI システムに特化した脅威モデリングサービスです。AIシステムの設計段階や導入検討段階において、脅威モデリングに特化したアーキテクチャ図の作成、セキュリティリスクの特定とマッピング、効果的な対策立案により早期のセキュリティ確保を支援します。詳細はこちら - AIシステムの包括的セキュリティ診断サービス(AI Red Team)
RAGシステムを含むLLMアプリケーションに特化したAIセキュリティ診断サービスです。プロンプトインジェクション対策の評価から機密情報漏洩対策、システム統合における脆弱性まで、専門家が診断。安全なシステム構築を強力にサポートします。詳細はこちら - AIシステムの継続的セキュリティ監視サービス(AI Blue Team)
AIシステムの継続的なセキュリティ監視を24時間365日提供するサービスです。独自開発の検知APIにより、リアルタイムで悪意のある入力(プロンプトインジェクションなど)や不適切な出力(機密情報漏洩など)を検知・ブロック。最新の攻撃手法に対応するインテリジェンスを提供します。詳細はこちら - AIリスクガバナンス構築支援サービス
ポリシー・ガイドライン整備から体制整備、具体的な対策の推進まで幅広く支援するサービスです。企業がAI技術を用いて事業や経営の変革を推進するにあたり、AI技術のセキュリティ・倫理・社会的影響・プライバシー/個人情報保護等に関する法規制対応といった課題解決やリスク管理を支援します。詳細はこちら -
AIセキュリティ対策 特設サイト はこちら

















