




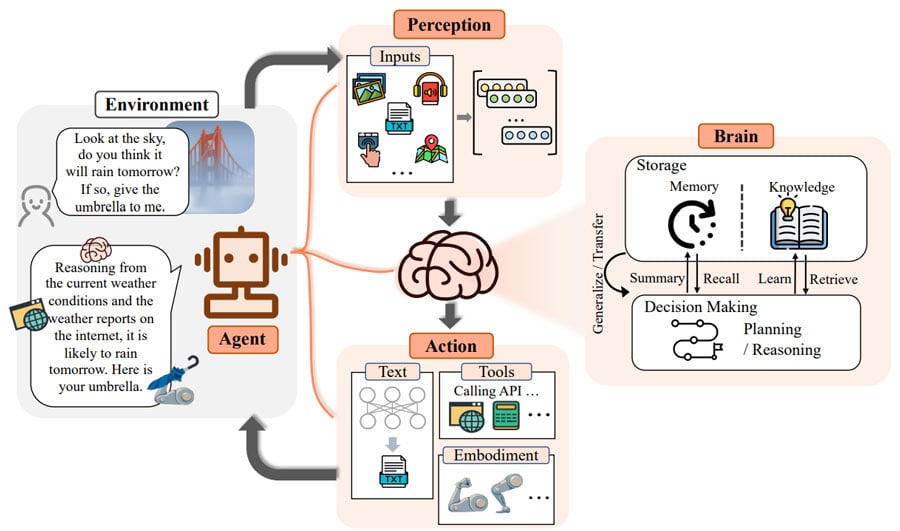
LLMを用いたマルチエージェントの背景と仕組み
昨年から話題を席巻しているLLMの応用として、AIエージェントが注目され始めています。AIエージェントは「置かれた環境に応じて自律的に行動できるAI」や「人の代理を担うAI(例:チャットボット)」を指しますが、本稿では特にLLMを基盤に据えたAIエージェントを取り上げます。
(出所)Park et al. Generative agents: Interactive simulacra of human behavior. 2023.


マルチエージェントの概要
LLMにテキストを生成させる際に役割や人格を記述したプロンプトを追加で注入すると、エージェントはこれに倣った振る舞いをすることが知られています(Role-Play Prompting)。これを応用することで複数のエージェントにそれぞれ異なる役割や人格を与えることができます。
さらに多彩な役割・人格を備えたエージェントにチームを組ませることで、単一のAIエージェントでは達成が困難なタスクであっても、比較的優れた成果を残せることが知られています。あるいは、AIエージェント同士の対話に人がエージェントとして混ざることが可能で、AIと人とを融合させたチームビルディングもできます。
このように複数のエージェントがチームワークすることで、より良い成果を目指せることがマルチエージェントの魅力といえます。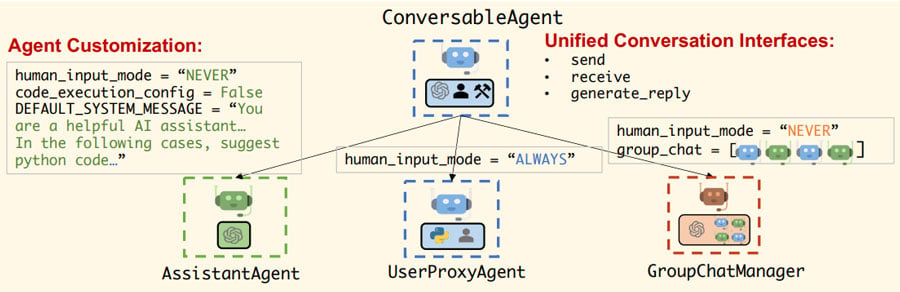
(出所) Wu et al. AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation. 2023.
Generative Agents
LLMを用いたマルチエージェントの先駆けとしてGenerative Agentsが挙げられます。ただし、同研究はマルチエージェントに特定のタスクを行わせることを目的にしていません。「25人が暮らす仮想の村で、ニュースは口コミでどのぐらい、どのように伝播するか」といった問いを明らかにする、いわば社会活動をシミュレーションすることが目的になっています。応用例のひとつChatDevでは、仮想のソフトウェア会社における各ポジション、すなわちエンジニアやデザイナー、レビュアー、テスター、経営層(CEO, CPO, CTO)を配置し、組織全体や役割毎の振る舞いを観察できます。
本稿では割愛しますが、Generative Agentsの内部実装にはマルチエージェントの展望を読み解くヒントが多分に含まれています。しかし、少なくとも現在の実装はあくまでシミュレーションに重きが置かれていて、社会科学的な関心に偏ったものといえるかもしれません。
(出所)https://github.com/OpenBMB/ChatDev
よりタスク実行の成果に重きを置いたマルチエージェントの実装としてAutoGenが挙げられます。ここではAutoGenを語る前に、関連する仕組みであるOpen Interpreterから説明しておきます。
Open Interpreter
Open Interpreterは、LLMが生成したプログラムをローカル環境で自動実行し、タスクを遂行できる仕組みです。従来LLMの用途は「尋ねる」「会話する」に尽きましたが、Open Interpreterの登場によって「(タスクを)やってもらう」ことが可能になりました。
タスクの詳細を記述したプロンプトを与えると、LLMは達成に向けた計画を生成します。計画にはコーディングはもちろん、コードを実行する為の環境構築(例:必要なソフトウェアのインストール)、コードの実行、あるいは実行結果の視覚化まで含められます。さらに実行結果は自身にフィードバックされ、そこにエラーが含まれる場合は計画を修正のうえ試行錯誤することもできます。
つまりOpen Interpreterでは計画・実行・検証・再計画を一貫してLLMに委ねられる、いわゆるPDCAサイクルを自動で回すことができます。そのため、エンジニアやデータサイエンティストのタスクの大部分をLLMに置き換えられる可能性を示唆しています。
AutoGen
AutoGenもOpen Interpreterと同様、「LLMにタスクをやらせる」を可能にする仕組みです。ただし、AutoGenでは複数のエージェントに異なる役割を持たせて、それぞれの立場や知見を生かしながらタスクを遂行する、いわばチームワークを可能にしています。
チーム構成を適切に行うことで、より目的に即した成果を生み出すことや、あるいは単一のAIエージェントでは遂行が困難だったタスクも遂行できるようになります。
チーム・組織のデザインパターン
マルチエージェントのチームビルディングには、成果の目的や性質に応じたデザインパターンが存在します。既知のパターンのうち一部を本セクションで紹介します。
また「デザインパターン」と聞くと小難しく聞こえるかもしれませんが、パターンのうち多くは既存の(人の)チームワークに見られた役割からのアナロジーで語ることができるので、パターンによっては馴染み深いものがあるかもしれません。
進行に応じて適切なエージェントへ発言権を与える
このパターンは従来の「ファシリテータ」に相当するエージェントをチームに加えたものです。
エージェントの発言機会は事前に決定することも可能ですが、こちらのパターンでは議論の進行や文脈に応じて、次に発言権を与えるべき相手(エージェント)を決めてもらうことができます。(仕組み上、他のエージェントの発言履歴を次に発言するエージェントへ伝播する役割も担っています。)
AutoGenではファシリテータに相当する「GroupChatManager」という特殊な役割が標準で用意されており、当該エージェントに対して特別なプロンプトを与える必要はありません。
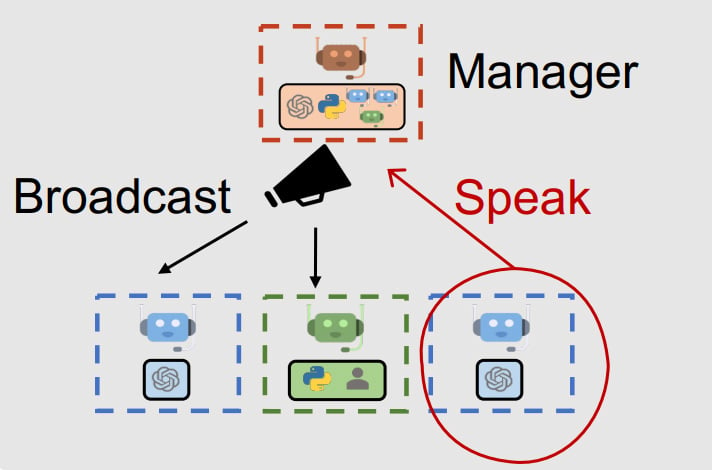
(出所) Wu et al. AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation. 2023.
タスクの成果に制約を与える
このパターンは「レビュアー」に相当するエージェントをチームに加えたものです。
チームワークの成果に一定の制約を与えたい状況は多々あります。具体的には以下のような状況が該当します。
- ユーザに夕食のレシピを提案するタスクで、味覚的な嗜好だけでなく健康や予算に気遣かった内容を提案したい。
- ソフトウェア開発を行うタスクで、ロジックにバグや脆弱性が含まれないようにしたい。
- 顧客からの質疑に応じるタスクで、コンプライアンスに則した発言をさせたい。
例えば、販売業務が規制の下にある場合(例:金融商品取引法など)、顧客と会話するチャットボットがレギュレーションに引っかかる発言をするリスクが想定されます。リスクを抑制する為、レビュアーに相当するエージェントをチームに加えることができます。
プロンプトを記述する際、レビュアーのエージェントに与える役割の名称は現実世界の語彙がそのまま通用することが多いです。つまりレシピ提案のタスクならば「医者」、ソフトウェア開発のタスクならば「コードレビュアー」、コンプライアンスに従った営業活動のタスクなら「法務担当者」といった要領です。
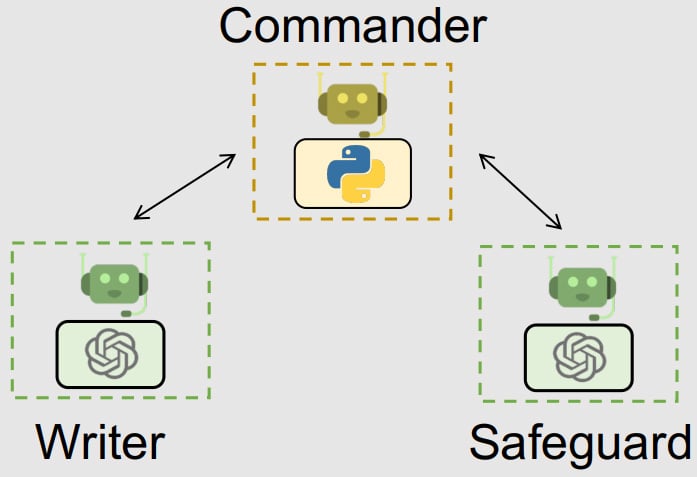
(出所) Wu et al. AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation. 2023.
タスクへの取り組み方について助言を与える
このパターンは「アドバイザー」に相当するエージェントをチームに加えたものです。
LLMが誤った回答を生成する場合、回答を導くまでの「考え方」を記述したプロンプトを追加で与えることによって、LLMが正しい回答を導けるようになることがあります。結論を導くまでの思考過程を複数のステップに分ける指示を与えるChain-of-Thought(CoT)、あるいは「思考・行動・結果の観察」を一連のプロセスとして繰り返し、より良い答えを導こうとするReAct等は、LLMに「考え方」を伝授することの重要性を証明しています。
AutoGenは前述のOpen Interpreterと同様、自身の行動結果を観察し、次回の行動の改善に活かすメカニズムを備えます。しかし、タスクの遂行に必要な考え方(問題のドメインにおける常識)が欠如することで、繰り返し誤った回答を導いてしまうループ状態に陥ることがあります。このような一種のスランプ状態からLLMを救うため、「考え方」のアドバイザーをチームに加えることは有効です。タスク遂行に求められる常識を蓄積したエージェントを配置することで、LLMが苦手なドメインに関するテキストを論理立てて生成できるようになります。
LLMが苦手なタスクの一例として、物体操作(物理現象)のプロセスを描写することが挙げられます。この問題を本パターンで解決する場合、物理現象に関する常識として“You must find and take the object before you can examine it.(物体を調査する前に、対象を見つけて手に取らなければならない。)”、” You must go to where the target object is before you can use it.(物体を使用するには、対象が置かれる場所へ行かなければならない。)”といった考え方をGrounding Agentに蓄積しておきます。物理シミュレータを操作するエージェントがGrounding Agentと連携することで、誤った操作のループ状態から抜け出せることがあります。Grounding Agentに蓄積された知見は、我々人間にとって「当たり前すぎて、かえって分かり難い」と思えるレベルの知見ですが、LLMにとって有用なこともあるのです。
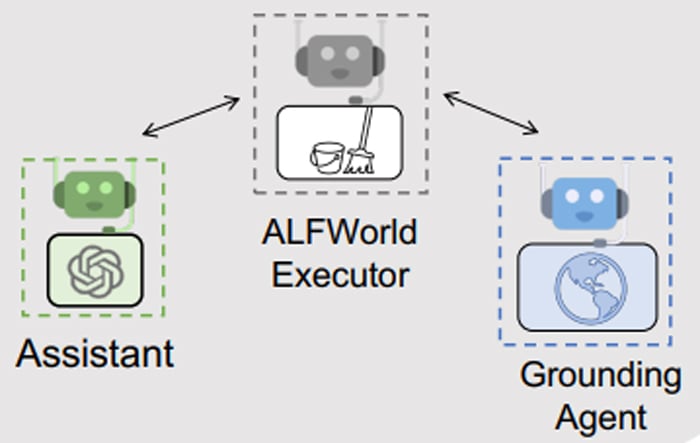
(出所) Wu et al. AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation. 2023.
役割に応じた専門知識・最新情報を与える
このパターンは「耳打ち役」あるいは「カンペ(カンニングペーパー)」に相当するエージェントをチームに加えたものです。
本パターンの主旨を掻い摘むと、AIエージェントが外側(例:ナレッジベース)から専門知識・最新情報を取得するための仲介役エージェントを導入することで、生成される回答を改善する仕組みです。医者なら医学書・カルテ、エンジニアなら技術書・仕様書、法務担当者なら法文・判例などといった具合に、AIエージェントの配役に応じたドメイン知識を深められる仕組みともいえます。
LLMのトレーニングに用いられた学習データやAutoGen設定時のプロンプトだけでは、タスク実行に必要な専門知識が不足している、あるいは論拠とする情報が陳腐化している恐れがあります。より良い成果を生み出すためには、エージェントに新鮮かつ大量の専門知識を与える必要があります。
よく知られる対策としてRetrieval Augmented Generation(RAG)が挙げられます。これはマルチエージェント以前から用いられていたテクニックです。プロンプトを受け付けた際、あらかじめナレッジベースからプロンプトの内容に関連の強い情報を取得し、「回答を生成する際のカンペ」としてLLMに与える手法です。高コストなファインチューニングを行わなくても、回答内容の鮮度を高める、あるいは専門性の高い回答を生成できることがRAGの魅力といえるでしょう。
本パターンのメカニズムも上記を踏襲した仕組みです。何かしらのトリガー(例:ユーザからの要求、生成した回答内容にエラーが含まれていた)を受けて、AIエージェントは外部から新たな知識を取得し、より良い回答の生成を試みます。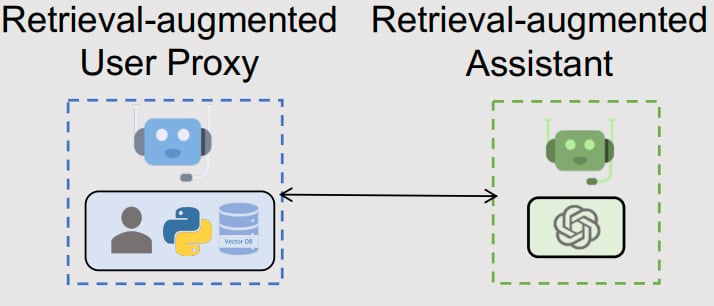
(出所) Wu et al. AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation. 2023.
まとめ
本稿ではLLMを基盤としたマルチエージェントを紹介しました。
- マルチエージェントは異なる役割や人格を与えられた複数のAIエージェントが協力することで、単一のAIエージェントよりも優れた成果を生み出せる仕組み。
- 従来LLMの用途は「尋ねる」「会話する」に尽きていたが、AutoGenとOpen Interpreterの登場によってLLMにタスクを「やらせる」ことが可能になった。なかでもAutoGenはマルチエージェント形式でタスクを遂行できる。
- マルチエージェントの構成、いわばチーム作りにはデザインパターンがある。デザインパターンの多くは、既存の(人の)組織づくりからのアナロジーで語ることができる。
<関連サービス>
参考:本著者の執筆記事
【解説】プライバシー保護の技術|PETs(Privacy-enhancing technologies)とは?

















