




その AI 本当に信頼できますか?
近年、AI技術は劇的に進化・普及しています。例えば、AIによる自動運転の実現や、囲碁・将棋などのゲームにおいてAIがプロの棋士に勝ってしまうなど、10年前には予想もしなかったようなことが次々と起きています。
しかしAIの進化は、我々に明るい話題だけでなく、同時に解決しなければならない多くの課題や不安をも提起します。話題に上りやすいものとしては、「AIに人が支配される」「AIがヒトの仕事を奪う」といったものがあります。これらも重大なテーマではあるかもしれませんが、ここでは、それらとは異なるテーマにフォーカスしようと思います。
この記事を読んでいるすべての方が、直接的・間接的にAIを活用した何らかのサービスを使われていると思います。典型的なものとしては、スマートフォンやスマート家電に組み込まれたアシスタント機能(AppleのSiri, AmazonのAlexa, GoogleのGoogleアシスタント等)が挙げられます。普段利用している様々なWebサービスの背後で、実はAIが利用されている、ということも多いと思います。
スマートフォンに質問したり、スマートスピーカに家の電気やエアコンの操作を任せたりする程度なら、AI が期待した動作をしなくてもさほど大きな問題ではなく、笑って済ませられるかもしれません。しかし、株式自動売買 AI が、あなたの大切な資産を一瞬で激減させてしまったら?自動運転車が事故をおこして大怪我をしたら?あなたの大切な人が AI を利用した医療判断のミスでその尊い命を失ってしまったら?
AIは我々の生活を豊かにするために必要不可欠なものとなるのは明らかに思えます。しかし、AIを『我々人間のパートナー』として手放しで信頼しても大丈夫なのでしょうか?
本シリーズでは、AI の「信頼性」という点において、どのような課題があり、その課題にどのように立ち向かっていくかをテーマにして、複数回に分けてその基本を解説していきます。本稿では、そのイントロダクションとして、AI の信頼性に関するキーワードとして話題になりつつあるTrustworthy AI とはなにか?についてその概要を説明します。

不可解なAI
AI の信頼性担保は、実はとても難しい問題です。その理由について、従来のコンピュータプログラム(以下プログラム)と現在の AI のモデル(AIの中核部分)の開発プロセスを比較しながら考察してみます。
従来のプログラム開発とAIのモデル開発との違いとは、何でしょうか?
一番大きな違いは、プログラム開発は「ヒトがロジック(プログラムの動作)を直接コントロールすること」であるのに対し、AIのモデル開発は「まっさらな下地(モデル)を、大量のデータで学習させること」であると筆者は考えます。
従来のプログラムでは、ロジックをヒトがコントロールすることも、その動作をヒトが説明することも可能です。
これに対し、モデルは、大量のデータを使ってモデルを学習させるため、ヒトがそのロジックを完全に把握してコントロールすることも、その挙動を説明することも極めて困難なのです。モデルが複雑になればなるほど、その傾向は強くなります。
しかし、難しいからと言ってあきらめるわけにはいきません。
AIに重要なことを任せようとすればするほど、AIは信頼に足るものであるべきです。「信頼できるAI」は、今後のAIの活用を進めていくうえで、必ず備えなければならない性質となります。これを"Trustworthy AI"と呼び、現在、世界中で活発な議論が行われています。
Trustworthy AI とは何か
Trustworthy (信頼できる) と一口に言っても、何をもって「信頼できる」と言えるのかは曖昧です。事実、Trustworthy AI を研究している組織はたくさんありますが、未だ標準的に「これがTrustworthy AIである」という定義・要素は定まっていません(考え方としては概ね同じ方向性ですが、分類方法や名称など、細部が異なります)。
Trustworthy AI を考える上での性質の分類方法も定まっていませんが、我々は、Trustworthy AIを、以下で説明する、Robustness (頑健性)、Explainability (説明可能性)、Fairness (公平性)、Privacy (プライバシー)の四つのカテゴリに分類して考察しています。それぞれのカテゴリについて、簡単に解説します。
Robustness (頑健性)
Robustness (頑健性)とは、悪意をもってAIに誤認識・誤判断を発生させようとする攻撃に対する耐性、言い換えれば「騙されづらさ」を指すと考えられます。
自動運転車のAIに対して、「進入禁止」の標識を、「制限速度50km/h」と意図的に誤解させてしまうことができてしまったらどうでしょう。
AIを信頼して運転を任せていたら、悪意のある人物によってAIが騙され、交通事故に遭ってしまう、などという事態が起きてしまっては大変です。
下記の画像は、画像認識において、道路標識を別の画像として誤認識させるという試みです。
 (出典) Chawin Sitawarin, Arjun Nitin Bhagoji, Arsalan Mosenia, Mung Chiang, Prateek Mittal, “DARTS: Deceiving Autonomous Cars with Toxic Signs” https://arxiv.org/abs/1802.06430
(出典) Chawin Sitawarin, Arjun Nitin Bhagoji, Arsalan Mosenia, Mung Chiang, Prateek Mittal, “DARTS: Deceiving Autonomous Cars with Toxic Signs” https://arxiv.org/abs/1802.06430
元々(上の画像)はそれぞれ時速80km、120kmを表す標識ですが、特殊なノイズ(摂動と呼ばれる)を施すことで、それぞれ「停止」「制限時速30km」に誤認識させることができています。また、一時停止の標識を速度制限標識に誤分類させる実験も存在します。このような実験と同じことを、実際の道路上でやられてしまった場合のリスクは語るまでもありません。
実用化されたAIは、このように「騙されやすい」ものであってはならず、Robustnessは、AIを実用化するうえでとても重要です。
Explainability (説明可能性)
Explainability (説明可能性)とは、AIが導き出した答えについて、「なぜその答えを出したのか」が説明できる能力の高さのことです。これは、特にAIが誤った答えを出したとき、その原因を追究・修正するために重要になります。
例えば、スマートスピーカに「電気をつけて」とお願いしたとしましょう。ところが、なぜかスマートスピーカは音楽を流し始めてしまった。あなたはため息をつきながら、自分の手で音楽を止め、電気をつけるでしょう。笑い話にでもするかもしれません。「電気をつける」だけなら、その程度の話で済みます。
では、レントゲンの画像診断で、がんの兆候を見過ごされてしまったら?いくら難しい問題であったとしても、当事者からしたら、「なぜ見つからなかったのか」を説明してほしいと思うのではないでしょうか。
下記の画像は、画像診断において、どの部分が診断結果に貢献したか、を可視化する試みです。一番右の画像(Heatmap)は、画像のどの部分が糖尿病性網膜症(Diabetic Retinopathy)のリスク判断に寄与したか、を可視化しています。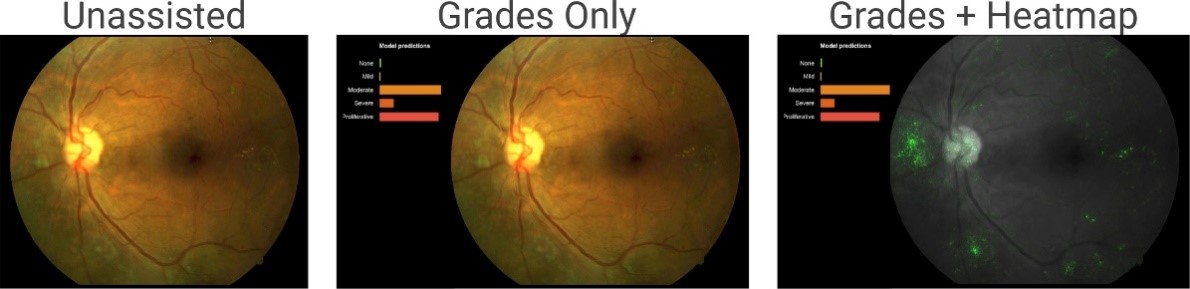
(出典) Rory Sayres, Ankur Taly, Ehsan Rahimy, Katy Blumer, David Coz, Naama Hammel, Jonathan Krause, Arunachalam Narayanaswamy, Zahra Rastegar, Derek Wu, Shawn Xu, Scott Barb, Anthony Joseph, Michael Shumski, Jesse Smith, Arjun B. Sood, Greg S. Corrado, Lily Peng, Dale R. Webster, “Using a Deep Learning Algorithm andIntegrated Gradients Explanation to AssistGrading for Diabetic Retinopathy”, https://www.sciencedirect.com/science/article/pii/S0161642018315756
このようなアプローチを採ることで、漠然と「病気の可能性がある」と言われるのではなく、「このあたりを見たところ、病気の可能性がある」という、より納得感のある回答を得られることになります。また、「病気の可能性がある」という診断結果が正当なものであるかどうか(誤診断なのかどうか)についても、このような視覚化の結果を用いて検証することができるかもしれません。
Fairness (公平性)
Fairness (公平性)とは、AIが社会的・倫理的に見てどの程度、公平な判断を行っているかを表します。
例えば、対象となる人物に対するローン審査(いくら借りられるか、利率はいくらか)をAIによって実行させたとします。この際、入力として、「性別」以外の情報がすべて等しい2つのプロフィールをAIに与えた際に、男性の方が女性よりも好条件を得られてしまう、というようなことが起きてしまったら、女性としては到底納得できません。
AIの仕組みそのものが人種や性別に対する偏見を持っている(製作者によって意図的にプログラムされた)わけではありません。AIを学習させる過程で偏りのある(言い換えれば偏見のある)データを与えてしまったため、AI自身が人間から見て偏見のある回答を返してしまうようになってしまう、という事象です。(他にも少数派のデータがモデルに反映されづらく、結果として不公平なモデルになるなど、不公平なモデルを生む原因は複数あります。)
過去の例ですが、Google翻訳において、人称代名詞に性別が存在しない言語(トルコ語)から存在する言語(英語)への変換を行った際、「医者」は「彼」、「看護師」は「彼女」という「偏見」を持った翻訳が行われてしまった、という例がありました。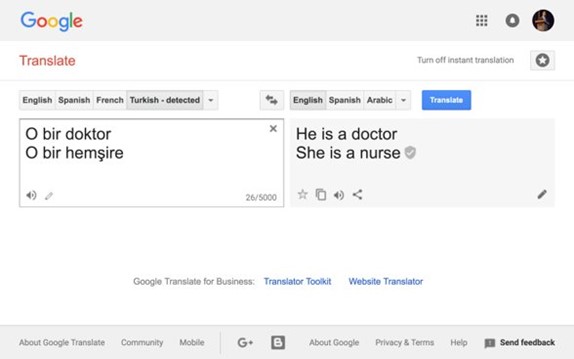
(本件は既に修正済みで、Google自身によって説明されています。)
人間がそうであることを求められるのと同様に、AIも公平な判断を行わなければなりません。
Privacy (プライバシー)
Privacy (プライバシー)とは、AIがプライバシーを守る、言い換えれば、AIから想定外の情報を引き出せないようにすることです。
AIのモデルを開発する際には、実世界のデータを大量に学習させます。この学習に使ったデータの内容を、AIの利用を通して引き出してしまうことができるのではないか、という懸念があります。学習に使ったデータは実世界に存在する誰か(何か)の情報となりますが、多くの場合、モデルの学習にデータを活用する際には、匿名性を守ることが前提となります。この匿名性が崩れてしまう、つまりプライバシー侵害が起きてしまうのではないか、という懸念です。
AIモデルの学習過程は、人間がたくさんの情報を「覚える」ことに似ています。
AIのモデルは、学習のために与えられたデータを詳細にすべて覚えている(データとして保存している)わけではありません。しかし、学習(自分自身の調整)を行った結果、モデルは与えられた学習データの痕跡(特徴)をその中に蓄えることになります。AIの学習のさせ方・質問の仕方によっては、AIの中に残る痕跡から、元のデータに近い情報を引き出すことが可能かもしれません。
例えば顔認識技術について考えてみます。人間が「人の顔」を認識するために、その人の特定の画像(いわゆる写真)をそのまま覚えるのではないように、AIも学習の仮定で「写真」そのものではなく、たくさんの「特徴」を覚えていきます。
覚えている情報は「写真」そのものではありませんが、そのAIの「特徴」から、元の「写真」に近い情報を引き出すことができるかもしれません。
下記の画像は、画像認識AIから、トレーニングに使われたオリジナルの画像の抽出を試みた論文によるものです。オリジナル画像そのものとはいかないまでも、かなり雰囲気のわかる画像になっています。
(出典) Matt Fredrikson, Somesh Jha, Thomas Ristenpart, “Model Inversion Attacks that Exploit Confidence Information and Basic Countermeasures”, https://rist.tech.cornell.edu/papers/mi-ccs.pdf より、筆者にて加筆
この分野はまだ研究の途上であり、まだ実用上問題となるような事件が発生したことも、当社で把握している限りありません。上記の論文の手法についても、当社でも検証を試みましたが、これだけはっきりとした復元を行うためには、かなりの好条件がそろっている必要があるのではないかと考えています。
しかし、プライバシーはとても大切です。プライバシー関連の技術動向を把握し、もしも懸念があるようであればそれに対する対策を打っていくことは、極めて重要です。
信頼できるAIとともに
AIは今後ますます進化していき、人間の重要なパートナーと見なされていくでしょう。
その時、あなたが「パートナー」に求めるものは何でしょう?
都合の悪いことは隠し、すぐに勘違いをし、差別的で、すぐに秘密をばらすような人よりも、誠実で(Explainability)、騙されることなく(Robustness)、公平で(Fairness)、秘密を守る(Privacy)人物の方が、パートナーとしてふさわしいと思うのではないでしょうか。
インターネットが一般に普及し始めた頃、数多くのサービスが矢継ぎ早に提供されていきましたが、その提供にあたってセキュリティを考慮したものはごく少数でした。しかし、いまやサービスを公開するにあたってセキュリティを考慮しないことなど考えられません。
AIの活用についても、同じことが言えるでしょう。デジタルトランスフォーメーションの一環としてAIの活用は急速に進んでいます。そんな中、Trustworthy AI のような考え方はようやく少しずつ気にされるようになってきた段階です。しかし、インターネットにおけるセキュリティ同様、Trustworthy AI はAIの利活用を進めるうえで必須のポイントになってくるであろうと考えます。
NRIセキュアのR&Dチームは、AIがより活用される未来に向けて、これらのAI利用に関するTrustworthy AIの検討を進めていきます。
本シリーズでは、我々の活動から得られた知見や見解を、できるだけわかりやすく、時には詳細に、解説していきたいと考えています。どうかご期待ください。
本ブログの執筆者が所属する研究チーム紹介ページはこちら!

















