




AIモデルはどのようにして我々のプライバシーを侵害するのか?
IT活用全般において、個人情報や企業の機密情報などの保護は、重要視されてきました。近年のITサービスの普及・グローバル化によって、各国がプライバシー関連の規制(GDPRやCCPA、改正個人情報保護法等)を相次いで打ち出していることからもわかるように、その重要性はますます大きくなっています。AI分野についても同様であり、プライバシーの保護は、AIを活用するうえでの前提として考えられるべきものです。
では、「AI活用におけるプライバシーリスク」とは具体的にどんなものなのでしょうか。
本連載の初回のブログでも述べた通り、一般にAIモデルを構成するにあたっては、大量の、多くの場合は実世界のデータ(学習データ)を使います。しかし、学習済みのAIモデルは学習に使ったデータをそのまま記憶しているわけではありません。あくまで学習によって得られた内部パラメータ、言い換えればデータの痕跡をその中に蓄えるだけです。
したがって、AIモデルからプライバシー侵害を誘発するためには、その「痕跡」から、元のデータに近しい情報の抽出・推定を試みることになります。この「抽出・推定」は、実際にどのようなプライバシー上のリスクとなり得るのでしょうか。例えば、個人の顔写真を学習データとしたAIモデルからは、その個人の顔写真を抽出できる可能性があります。音声認識からは個人の声が、指紋認証装置からはその個人の指紋を取り出すことができるかもしれません。
もしもAIサービスがプライバシー侵害に結果的につながるのであれば、AIサービスを提供する事業者としても、知らず知らずのうちにGDPR等の規制を侵害する結果となり、多額の罰金を科されてしまう可能性もあります。
以降では、なぜこのような問題が発生するかどのような緩和策があるかを複数回に分けて、解説していきます。今回は、Model Inversion Attack と当社での検証による考察を述べます。

学習データを復元する攻撃(Model Inversion Attack)
Inversion(反転・逆転)という言葉が示す通り、モデルの入力と出力を反転させる手法です。例えば、顔認識を行うモデルについて考えてみます。
このモデルは、「顔写真」を入力、「人名」を出力とする分類モデルです。このモデルに対するModel Inversion Attackにおいては、「人名」を入力として、「顔写真」を出力させることを目指します。
本シリーズ初回に記載した画像の再掲となりますが、論文では、下記のように画像の抽出に成功しています。(ただし、これから述べるように、これだけの鮮明な画像を得るには、かなりの好条件が必要になるのではないかと考えています。)
 (出典) Matt Fredrikson, Somesh Jha, Thomas Ristenpart, “Model Inversion Attacks that Exploit Confidence Information and Basic Countermeasures”, https://rist.tech.cornell.edu/papers/mi-ccs.pdf より、筆者にて加筆
(出典) Matt Fredrikson, Somesh Jha, Thomas Ristenpart, “Model Inversion Attacks that Exploit Confidence Information and Basic Countermeasures”, https://rist.tech.cornell.edu/papers/mi-ccs.pdf より、筆者にて加筆
攻撃の基本的なアイデアを簡単に説明します。スタート地点となる画像(真っ黒、真っ白など)を用意して、画像の画素(pixel)を少しずつ調整しながら、ターゲットとなる人名の判定結果(スコア)が上昇するように、何回もモデルによる判定を繰り返します。
イメージとしては、白紙の上に描いた絵を少しずつ変化させながらAIモデルに入力して反応(出力)を確認し、より目的の人物に近づけていくような感じです。ここでは、技術的な詳細解説は避けますが、手掛かりなしに闇雲に変化させるわけではなく、勾配降下法と呼ばれる合理的な手法を用いて画像を近づけていきます。
なお、勾配降下法でこの攻撃を実現するためにはモデルそのものが手中にある必要があり、例えばインターネット上に公開されている、判定結果のみをレスポンスとして返すようなAIサービスに対してはこの手法による攻撃はできません。
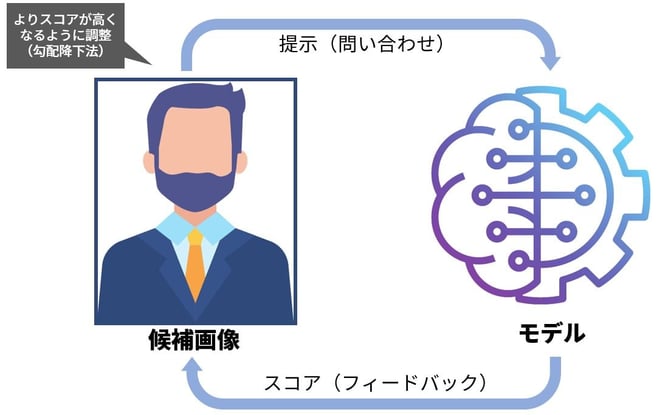
仮にこの手法が成功すると、AIモデルから、個人の顔・声・指紋といった、非常にセンシティブな情報を引き出すことができることになります。プライバシー侵害の問題だけではなく、例えば、認証プロセスにも悪用された場合のインパクトは計り知れないものになるでしょう。
認証突破は究極的にはあり得るかもしれませんが、確かに話がぶれそうな気がしますね。
どの程度危険な攻撃なのか?
ここで注意すべきなのは、ここで得られるデータは、学習に使われたデータそのものではなく、「そのAIモデルが正解に近いと判定した」データです。この手法情報を抽出されることが情報漏洩に当たるのかどうか、に関しては議論がありますが、Algorithms that remember: model inversion attacks and data protection law では、モデルそのものが個人情報とみなされ、GDPRに抵触する可能性を提起しています。
議論はモデルの漏洩についてなされていますが、根拠としてModel Inversion Attackや次回説明するMembership Inference Attack の成立可能性が指摘されています。
また、この手法によってどれだけ精密な(意味のある)情報にたどり着けるかには、複数の要素が関わってくるようで、当社での再現検証でも、まだ安定した結果を出すことができていません。
下記は、MNISTと呼ばれる、AIの研究によく用いられる手書きの数字画像集を用いた検証例です。なんとか読めそうなものもあれば、まったく成立していないものもあります。
モデル作成の際の条件(乱数)を変えて何度もテストしてみたところ、実行のたびに大きく異なる結果になりました。

図 元画像の例
 図 当社にてModel Inversion Attackの再現検証を行った結果の一例
図 当社にてModel Inversion Attackの再現検証を行った結果の一例
MNISTのような簡単なデータであっても、画像の復元は簡単ではありません。
これがより複雑な「特定の個人の顔」であったり、「車」「飛行機」などといったより抽象度の高い(一つの言葉が内包する概念のバリエーションが広い)分類を行うようなモデルを対象とする場合、意味のある画像を得るのはより難しくなります。
このように、Model Inversion Attackには、様々な条件が絡んでおり、実際に攻撃を成立させるのは容易ではないと考えられます。しかし、この手法をより洗練させる、特殊な条件を満たすモデルを攻撃対象とする、スタート地点として、真っ白・真っ黒ではなく、画像生成のためのヒントとなるもの(輪郭など)を与えるなど、活用の可能性はありえます。例えば、前述のMNISTを用いた評価に対して、スタート地点として全ての画像のそれぞれの画素(pixel)の平均(mean)を取ったものを与えた場合、このようになります。先ほどの図に比べて、可読性がかなり高まっていることが分かります。

図 学習データの平均
 図 学習データの平均値をスタート地点として、Model Inversion Attackを実行した例
図 学習データの平均値をスタート地点として、Model Inversion Attackを実行した例
ただし、いつでも学習データの平均から始めればうまくいくとは限りませんし、そもそもその「平均」を得ることが難しいことのほうが多いはずです。平均データを作成するために学習データそのものが得られているのであれば、この攻撃を実行するモチベーションはすでにないとも言えます。 ただ、このように、「付加的な情報を与えて入力とする」ことで、より精度の高い結果を得られる可能性があるのではと我々は考えています。
どのように AI のプライバシー問題と向き合うか?
今回は、AI モデルに対する攻撃手法の例として、Model Inversion Attackについて、当社の実行結果を交えて解説しました。
実行結果を見てわかるとおり、Model Inversion Attackには不安定なところがありますし、まだ実際の攻撃被害事例のようなものは当チームの知る限り確認されていません。しかし、AI 分野に限らずプライバシーに関する懸念は世界的に高まっており、前述のとおり攻撃が成立したときに想定されるインパクトが大きくなる可能性を秘めていることから、(インターネットセキュリティ分野がそうであったように)攻撃が一般化・深刻化していない頃から可能性について検討を行うことは重要だと考えます。
AIモデルに対するプライバシー攻撃の手法として、もう一つ著名なものに、Membership Inference Attackがあります。この手法は、データの復元ではなく、特定のデータが学習データに含まれているのかどうかを推定します。プライバシーテーマの次回は、Membership Inference Attackについて解説します。
本ブログの執筆者が所属する研究チーム紹介ページはこちら!

















