



 前回のブログでは、AI を騙す敵対的サンプルの具体的な脅威例を、研究成果をもとに説明しました。「AI を騙すなんて特殊な知識や能力を必要とし、敷居がとても高いのではないか?」と思った方もいるかもしれません。しかし、敵対的サンプルの生成は、シンプルなアイデアに基づいており、理解してしまえば簡単に生成できてしまいます。
前回のブログでは、AI を騙す敵対的サンプルの具体的な脅威例を、研究成果をもとに説明しました。「AI を騙すなんて特殊な知識や能力を必要とし、敷居がとても高いのではないか?」と思った方もいるかもしれません。しかし、敵対的サンプルの生成は、シンプルなアイデアに基づいており、理解してしまえば簡単に生成できてしまいます。
今回は続編として敵対的サンプルがどのように生成されるのかと、それを悪用した攻撃の分類について解説します。本稿で紹介している敵対的サンプルを作るプログラムは、Jupyter Notebook形式で公開していますので自身で敵対的サンプルを生成してみたいという方は併せてご覧ください。
なお、敵対的サンプルは前回のブログでも取り上げたとおり、様々な種類のモデルで脅威となり得ますが、どのモデルが対象であれ基本的な考え方は同じです。したがって、本稿では分かりやすさを優先し、画像の分類モデルをベースに解説します。


分類モデルとは?
敵対的サンプルは主に、ディープラーニングのモデル(DNN)のコンテキストで語られます。DNN が解く問題には大きく回帰問題と分類問題と呼ばれるものがありますが、敵対的サンプルは主に分類問題を解くモデル(分類モデル)の攻撃に利用されるものです。したがって、予備知識として分類モデルとはどういうものかを簡単に解説します。
例えば、なんらかの画像があったときにそれを犬、猫、猿のいずれかに分類したいとしましょう。本稿ではその分類先をクラスと呼びます。そのために作られるモデルは、画像を入力すると、犬、猫、猿に分類するモデルです。この分類モデルは、犬、猫、猿に関する大量の画像を学習データとして利用して学習します。厳密性には欠けますが、このモデルは学習データをもとに入力空間上に下図のような境界線をつくるイメージを持っていただくと以降の理解が捗ると思います。
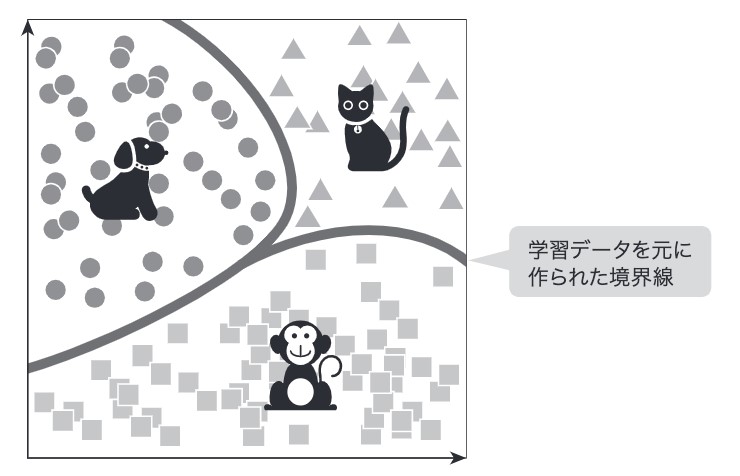
図 1:入力空間上の境界線のイメージ
分類モデルはなんらかの画像を入力すると、犬、猫、猿のそれぞれのスコア(確率のようなもの)を出力します。例えば、犬:0.9、猫:0.02、猿:0.08というスコアを出力した場合、最もスコアの高い『犬』と分類するといった具合です。
敵対的サンプルの基本的なアイデア
敵対的サンプルの生成アルゴリズムは様々ありますが、前回のブログでも引用した以下のパンダを手長猿に誤分類させるデモで有名な論文をベースに解説します。

図 2:少しのノイズでパンダを手長猿と誤分類
出所:Ian J. Goodfellow et al. “Explaining and Harnessing Adversarial Examples,” International Conference on Learning Representations (ICLR), 2015.
本論文で紹介されている、アルゴリズムは Fast Gradient Descent Method (FGSM)と呼ばれるものです。
前回のブログで、「敵対的サンプルとは、モデルに誤分類を引き起こさせるために、人間にはわからないようなわずかなノイズ(一般的に摂動と呼ばれます)を加えた画像などを指します。」と説明しました。今回はもう少し掘り下げて見てみましょう。
例えば、オリジナルのパンダ画像 があったとし、これに人間にはわからないようなわずかなノイズを加えて手長猿と誤分類させたいとしましょう。簡単のため、攻撃対象モデルは、パンダか手長猿のいずれかに分類させるモデルとします。この問題を解くために、下図のようにパンダと手長猿の境界線が引かれているイメージです。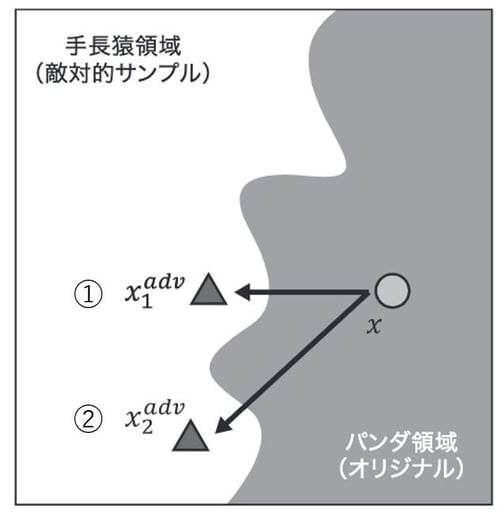
図 3:入力空間上での境界線と移動のイメージ
この時、敵対的サンプルはオリジナルのパンダと分類される画像を手長猿の境界線を超えて、手長猿に分類される領域に移動させるイメージです。「ノイズを加える」という行為は、この空間上で「移動を発生させる行為」というイメージを持ってください。ノイズが小さければ小さく移動しますし、大きければ大きく移動します。ノイズが大きければ大きいほど、画像は不自然なものとなります。
もちろん、あまり深く考えずに大きく移動させれば手長猿領域に移すことは可能ですが、それではノイズが大きくなるため人間の目にきづかれやすくなります。そこで、「可能な限り最短距離≒ノイズが少ない」で移動させることが敵対的サンプル生成アルゴリズムの基本的なアイデアです。例えば、図中の②よりも①への移動の方が、距離が短いので、ノイズは少なくて済みそうだというのは直感で理解できますね。
どうやって、「その方向を決めるか?」についてですが、ここでは勾配と呼ばれるものが使われます。パンダのスコアを大きくしたい場合、入力をどの方向に動かせば最も効率的にスコアを大きくすることができるかは、勾配を計算することで知ることができます。この勾配とは『逆の向き』に画像を移動させることで、効率的にパンダのスコアが小さくなり、結果として別のクラス(この例だと手長猿)に誤分類させることができるというカラクリです。
敵対的サンプルの実験の説明の前に、勾配の向きに移動させた場合はどうなるかについて見てみましょう。下図は、チワワのスコアを大きくする向き、つまり勾配を計算して、その向きに移動させたものです。左上の図が、オリジナルの画像で83.65%のスコアでチワワと分類されています。右上が、小さいノイズを加えたものでスコアが90.06%と向上していますね。さらに、ノイズを大きくした、左下は99.63%とさらにスコアを上げることに成功しています。(epsilon がノイズの大きさを表しています)
一番右下は極端にノイズのレベルを大きくしたもので、不自然な画像になっている上、スコアもかえって低くなっています。これはやり過ぎのケースです。
図 4:勾配の向きに移動させた例
サンプルコードはここに公開しています。
今度は、勾配とは逆の向きにノイズを加えた場合を見てみましょう。
図 5:勾配とは『逆の方向』に移動させた例(敵対的サンプル)
左上がオリジナルの画像です。右上は小さなノイズを加えることで、スコアを83.65%から74.16%に小さくすることに成功しています。もう少しノイズを大きくした左下は、オリジナル画像と全く違いがわかりませんが、チワワではなくスコアが 91.25% でポメラニアンに誤分類させることに成功しています。これがまさしく敵対的サンプルです。
なお、右下はさらにノイズを大きくしたものでポメラニアンに誤分類させることに成功はしていますが、画像が不自然になっており人間の目にも攻撃っぽく見えてしまいやり過ぎのケースと言えます。
非標的型攻撃と標的型攻撃
敵対的サンプルの基本的な仕組みがわかったところで、非標的型攻撃と標的型攻撃について説明します。敵対的サンプルによる攻撃は、非標的型攻撃と標的型攻撃と呼ばれる2つに分類されることがあります。非標的攻撃は、オリジナルクラス以外のクラスに誤分類させる攻撃で、標的型攻撃はオリジナルクラス以外の「任意の狙ったクラス」に誤分類させる攻撃です。先ほどの、FGSM は非標的型攻撃に分類されます。(厳密には標的型攻撃、非標的型攻撃のいずれにも適用可能ですが、オリジナル論文が扱っている非標的型攻撃をベースに解説しました。)
非標的型攻撃と標的型攻撃の違いを直感的に解説します。
非標的型攻撃は下図が示すように、なるべく短い移動距離でオリジナルのクラスの領域から別のクラス領域に誤分類されるように移動させる攻撃です。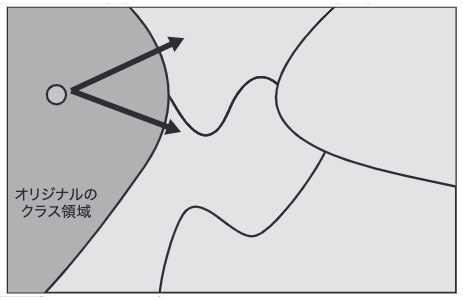
図 6:非標的型攻撃のイメージ
一方で、標的型攻撃はターゲットとするクラス領域に目掛けて移動します。標的型攻撃の場合は、ターゲットクラスのスコアが大きくなる入力の向きを探してその向きに入力を移動させることです。
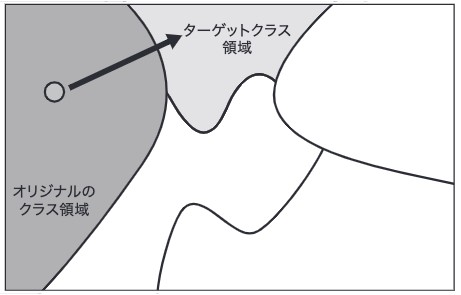
図 7:標的型攻撃のイメージ
この2つの違いは生成方法のみに注目すべきだけではなく、脅威レベルの違いに着目すべきだと筆者は考えます。例えば、道路交通標識を誤分類させる例を考えてみましょう。非標的型攻撃で、徐行標識を闇雲に誤分類させて、一時停止標識に誤分類させるよりも、速度制限60km/hの標識に誤分類させたほうが攻撃成功時の被害は大きくなることは容易に想像できますね。
ホワイトボックス攻撃とブラックボックス攻撃
敵対的サンプルの攻撃は、ホワイトボックス攻撃とブラックボックス攻撃で分類されることがあります。もう少し細かく分類されることもありますが、ここではこの2つの分類で解説します。
ホワイトボックス攻撃
ホワイトボックス攻撃は、手元に攻撃対象のモデルがあってそのモデルの詳細を知っていて初めて敵対的サンプルを生成できる状態での攻撃を指します。先に説明した FGSM では勾配を頼りにしており、勾配はモデルが手元にあってはじめて計算できるものです。したがって、FGSM はホワイトボックス攻撃に分類されます。FGSM 以外の勾配を頼りにした多くの生成アルゴリズムもホワイトボックス攻撃に分類されます。
ブラックボックス攻撃(Boundary Attack の例)
敵対的サンプルは勾配を頼りに生成するものであれば、「そもそもモデルがなんらかの方法で盗まれる可能性がなく、広く公開された誰でも入手可能なモデルを使っていなければ攻撃リスクは極めて低いのではないか?」と思った方もいるかもしれませんが、残念ながら答えは No です。というのは、手元にモデルがなくても敵対的サンプルを生成することは可能だからです。このような攻撃をブラックボックス攻撃と呼びます。
ブラックボックス攻撃に分類される生成アルゴリズムはいくつかありますが、Boundary Attack と呼ばれる生成アルゴリズムをベースに説明します。
Boundary Attack の論文は以下で参照できます。
説明のため、スマホで画像をアップロードするとその画像を分類するサービスを攻撃対象とすると仮定しましょう。このサービスは、分類モデルを利用しており、アップロードされた画像の分類結果とそのスコアのみをユーザに返します。もちろんユーザは直接的に分類モデルへはアクセスできません。
人間の目にはチワワにしか見えない画像をアップロードしてピザに誤分類させる行為を攻撃シナリオとしましょう。誤分類先のクラスに分類される画像、この場合はピザの画像をスタート画像、人間の目が分類するクラスの画像、この場合はチワワの画像をオリジナル画像と呼ぶことにします。
Boundary Attack は、入力空間上でスタート画像をオリジナル画像に少しずつ近づけていきます。イメージは下図の通りです。
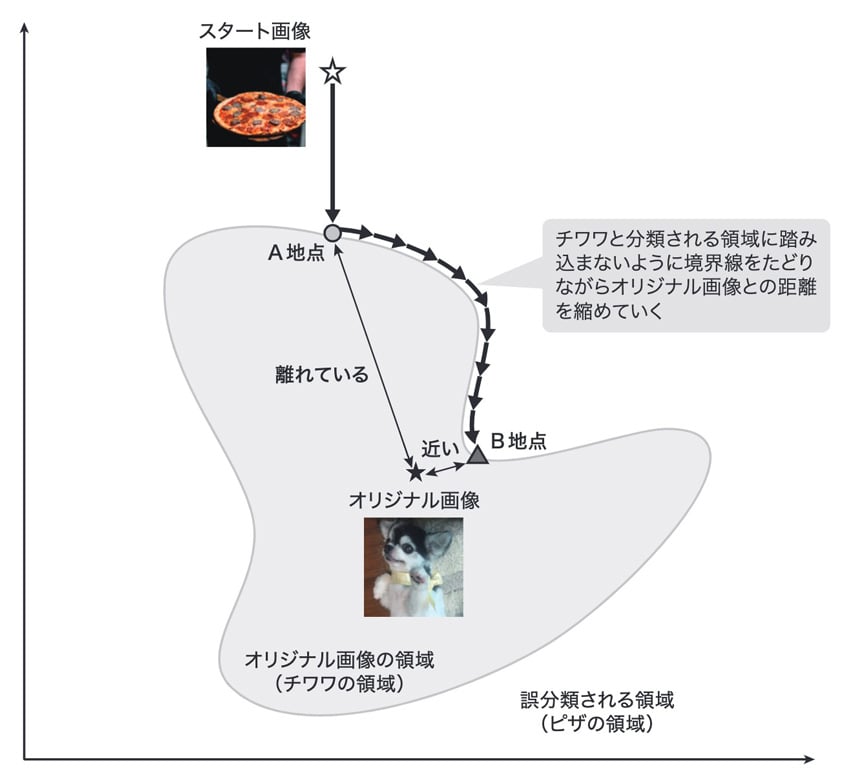
図 8:Boundary Attack のイメージ
図が示すように、チワワと分類される領域に踏み込まないように、ピザに分類される領域内でスタート画像を移動させていくイメージです。A地点でもピザと分類されますが、B地点の方が、オリジナル画像からの距離が近いので、その分ノイズが小さく敵対的サンプルとして優れているのは直感で理解できますね?この図の通り、Boundary Attack はオリジナル画像に分類される領域への境界線(Boundary)を辿りながらオリジナル画像に近づけていく方法です。この攻撃を実行する際には、画像をアップロードして、分類結果とスコアを得てその情報を頼りにオリジナル画像に近づけるという行為を何度も繰り返します。
下図は、ステップごとにどのようにオリジナル画像が変化したかを表しています(Jupyter Notebook はこちらに公開しています)。左上がオリジナル画像です。例えば、上段の左から2番目の500ステップの図は、うっすらとピザの画像が残っていますが、下段右の 4500ステップでは、ピザの画像は消えています。この画像はチワワに見えますが、ピザと誤分類される敵対的サンプルです。

図 9:ピザの画像がBoundary Attackによって徐々にチワワの画像に近づいている様子
なお、Boundary Attack によって敵対的サンプルを生成するには、一般的に相当数のリクエスト(画像アップロード)を送らなければならないため、レートリミットなどによりアクセスを制限することによって一定レベルの緩和策とはなり得えると思います。
Transfer Attack の脅威
しかしながら、仮にそのような緩和策で攻撃を防げたとしても、それとは別に、Transfer Attackと呼ばれる攻撃の脅威は残るので説明しておきます。
Transfer Attackとは一種のブラックボックス攻撃です。標的モデルが手元にないときに、代わりに手元にある別モデルを代理モデルとし、代理モデル上で敵対的サンプルを生成して、それを標的モデルへの攻撃に利用します。Transfer(転送)と呼ばれている由縁はここにあります。あるモデルで生成した敵対的サンプルを別のモデルに入力すると、相応の確度で誤分類を引き起こすことができるという実験結果があります(ただし、ホワイトボックス攻撃ほど成功率は高くありませんし、意図したクラスに誤分類させる標的型攻撃が難しいという問題もあります)。したがって、仮に提供するサービスのモデルが攻撃者の手に渡ることが絶対にないという前提に立ち、ホワイトボックス攻撃へのリスクを考えないことにしたとしても、Transfer Attackによる攻撃が成立してしまうリスクは残ります。
まとめ
敵対的サンプルの仕組みとその分類について解説しました。基本的なアイデアは比較的シンプルであり想像より理解は簡単であったと思っていただけたのでしたら幸いです。
本稿は、拙著「AIセキュリティから学ぶ-ディープラーニング[技術]入門」をベースにしています。本稿では数学や実装レベルでの説明ではなく直感的に理解いただけるように努めましたが、書籍では数学や実装レベルで理解できるように詳細な解説をしています。また、本稿では、生成アルゴリズムとして FGMS と Boundary Attack を取り上げましたが、その他の代表的なアルゴリズムも取り上げてありますのでより広く知りたい方は是非ご覧ください。
ここまでで、敵対的サンプルを悪用した攻撃の説明は一通り済んだので、次回からは如何にして守るか?つまり防御方法について取り上げる予定ですので、楽しみにしていただけたらと思います。

















