




AI のセキュリティはすべての人に関係あるの?
本稿は、AI の Robustness(頑健性) に関する記事の第一弾として、AI のモデルに対して誤認識を発生させようとする攻撃について解説します。近年、特にディープラーニングのモデルを意図的に騙す敵対的サンプル(adversarial example)と呼ばれているものを悪用した攻撃がセキュリティ上、懸念されています。
前回のブログで、意図的に自動運転車に道路標識を誤認識させる研究について紹介しましたが、これも敵対的サンプルの例です(敵対的サンプルの仕組みは後述します)。「自動運転車に道路標識を誤認識させる」という脅威は生命に影響を与える可能性のある非常にわかりやすい恐ろしい例ですが、敵対的サンプルによる脅威は、より広い領域で懸念されるべきものだと筆者は考えます。
本稿では、敵対的サンプルの脅威は、「AI を活用したサービス事業者やそれらを利用するユーザ、つまり AI に関わる全ての人が意識した方がよい問題」だということを実感していただくべく、敵対的サンプルの仕組みを簡単に解説した上で、自動運転領域以外の領域での脅威も研究をベースに複数紹介します。


敵対的サンプルとは
敵対的サンプルとは、モデルに誤分類を引き起こさせるために、人間にはわからないようなわずかなノイズ(一般的に摂動と呼ばれます)を加えた画像などを指します。敵対的サンプルを利用して誤分類を引き起こすまでを含めて「敵対的サンプル」と表現されることがありますが、本稿では、あくまで敵対的サンプルは「誤分類を引き起こすためにノイズが加えられた何らかのモノ」という定義で解説します。
また、敵対的サンプルを利用して誤分類を引き起こす行為を「攻撃」と呼びます。敵対的サンプルは画像分類に限らず、音声認識や物体検知といった分類モデル全般に対しての脅威となり得ます。
仕組みを簡単に解説します。AI のモデルは学習すると一定の推論能力を持つようになります。不動産価格予測であれば実際の売買価格に近い価格を出力できるようになり、画像分類の場合は正しい分類結果を返すようになります。
しかし、モデルは完璧ではなく、実際の売買価格とかなり乖離した価格を予測することもありますし、犬を猫と分類してしまうこともあります。特に分類問題において、この不完全さを悪用し、「意図的に」異なるクラスに誤分類させることが可能です。
下図を見てください。

図 1:少しのノイズでパンダを手長猿と誤分類
出所:Ian J. Goodfellow et al. “Explaining and Harnessing Adversarial Examples,” International Conference on Learning Representations (ICLR), 2015. https://research.google/pubs/pub43405/
これはGoogleの研究者の論文に挙げられていた画像です。一番左はパンダの画像です。一番右はどうでしょう?パンダでしょうか?どう見てもパンダにしか見えませんね。しかし、この画像を分類したモデルは一番左の画像をパンダと分類しますが、一番右は手長猿(gibbon)と誤分類します。真ん中の画像(厳密にはそれに定数を掛け算したもの)をノイズとして左の画像に加えると手長猿と誤分類するようになるのです。
この結果が示すように、人間の目が分類するのとは明らかに異なるクラスに「意図的に」誤分類させられてしまう脅威が存在するのです。
そして、ポイントはこのノイズがデタラメに作られたものではなく、数学を根拠に計算して作られたという点です。つまり、AI にはわずかなノイズで誤分類を「意図的に」引き起こされる脆弱性が存在すると考えることもできます。
敵対的サンプルの脅威例
以降で、敵対的サンプルが近い将来、我々の日常生活でどのような脅威となりえるかについて、研究結果を元に考察してみましょう。
顔認証システムでのなりすまし
スマートフォンのロック解除を顔認証でできるようになるなど AI を利用した顔認証システムが身近なものになりつつあります。また、現時点では、企業の入館において、カード型の社員証などをセンサーにかざして認証に成功した場合のみゲートが開くという入館システムが一般的ですが、カードの代わりに顔認証システムを利用する企業も出てきています。
同時に、顔認証システムにおいて他人になりすますための研究もされています。ここでは、「敵対的メガネ」(adversarial eyeglasses)という敵対的サンプルとして生成されたメガネを着用して他人へのなりすましに成功した研究を紹介します。
Mahmood Sharif et al., “A General Framework for Adversarial Examples with Objec-tives,”ACM Transactions on Privacy and Security, ACM, June 2019 https://dl.acm.org/doi/10.1145/3317611
次の画像を見てください。

図 2: 敵対的メガネのデモの様子
出所: 論文著者の研究チームが公開しているデモ動画から筆者が一部スナップショットしたもの
https://bit.ly/33UWBK1
図2の画像は、論文著者の研究チームが公開しているデモ動画から筆者が一部スナップショットしたものです。
デモ動画のURL
https://bit.ly/33UWBK1
なりすまし先のArielという名の女性の画像は同チームのカンファレンスでのスライドから引用しています。メガネを掛けたり外したりしている男性は、Mahmoodという名前の人物です。
Arielという人物の画像の引用元(同チームのカンファレンスでのセッションのスライド)Lujo Bauer, “On the Susceptibility to Adversarial Examples Under Real-World Constraints,” SlidesLive, Apr 26, 2020.
図2のMahmoodは、左から順に、普通のメガネ着用、メガネ未着用、非敵対的メガネ着用、敵対的メガネ着用の状態です。敵対的メガネを着用しない状態では、いずれも0.99~1.00のスコアで正しくMahmoodと分類できていますが、敵対的メガネを着用した状態だと、Arielという人物になりすませているのがわかります。
この例が示すように、たとえば、不審者が社員になりすまして企業に侵入するといった物理セキュリティでの脅威が考えられます。
物体検知の回避
物体検知とは、簡単に言うと画像内の物体を検出する技術で、DNNを応用して実装されています。物体検知は一般的に物体を検知してから、なんらかのクラスに分類します。物体検知は自動運転などの周辺状況の把握に利用されるだけではなく、侵入者を検知する防犯カメラなどの物理セキュリティにも応用可能です。しかし、物体検知を回避する研究も同時に行われており、回避に成功した実験結果もあります。Zuxuan Wuらの論文から引用した下図を見てください。

図 3: 真ん中の人物は、特殊な模様の洋服を着て物体検知を回避
出所:Zuxuan Wu et al., “Making an Invisibility Cloak: Real World Adversarial Attacks on Object Detectors,”arXiv:1910.14667, 2020.
https://arxiv.org/abs/1910.14667
この図は、物体検知を回避しているデモの様子を見せています。
このデモで利用されている対象の物体検知モデルは「YOLOv2」と呼ばれる、物体検知としては非常に著名なモデルです。YOLOv2 は9000種類の物体検知が可能です。画像中の四角の箇所は人間を検知しているセグメンテーションを表します。おおむね人間を検知できていますが、真ん中で堂々と立っている人物はなぜか検知されていません。理由は、特殊な模様がプリントされた洋服を着用しているためです。着用している洋服が敵対的サンプル、特殊な模様がノイズ相当です。
この研究は静止状態での検知回避なので、動きを伴う検知回避で利用するには実用性に欠けますが、移動する人物でも検知を回避可能な敵対的Tシャツ(Adversarial T-shirt)という敵対的サンプルの生成に成功した例もあります。次のKaidi Xuらの論文で紹介されているものを紹介します。
Kaidi Xu et al., “Adversarial T-shirt! Evading Person Detectors in A Physical World,”arXiv:1910.11099, 2020.
この論文では、Tシャツのような非剛体に対して変形の影響をモデル化した初めての研究成果と主張しています。次のデモを見てください。先ほどと同じく、YOLOv2の検知を回避しています。

図 4: 右側の敵対的Tシャツを着た人物が歩きながらも物体検知を回避しているデモ
出所:Kaidi Xu et al., “Adversarial T-shirt! Evading Person Detectors in A Physical World,”arXiv:1910.11099, 2020.
https://arxiv.org/pdf/1910.11099.pdf
図4 の一番右の「pattern」の画像は、敵対的Tシャツの模様です。残りの画像は、向かって歩いてくる2名に対してYOLOv2が物体検知している様子です。敵対的Tシャツではない洋服を着ている左の人物は検知されていますが、右の人物は敵対的Tシャツを着用しているため、検知されていません。
この研究では、物理世界で57パーセントの攻撃成功率と報告しています。これらの例が示すように、顔認証システムでのなりすましや物体検知モデルの検知を回避する敵対的サンプルは物理セキュリティの脅威となり得るということがご理解頂けたかと思います。
マルウェア検知の回避
マルウェア検知において、従来のシグネチャベースやルールベースでの検知では未知のマルウェアに対応するのが難しいため、DNNを含めた機械学習が利用されるようになってきました。
しかし、同時にその検知を回避するようにマルウェアを生成する攻撃者も現れてきています。ここでは、マルウェア検知領域における敵対的サンプルを紹介します。
Mahmood Sharif et al., “Optimization-Guided Binary Diversification to Mislead Neural Networks for Malware Detection,” arXiv:1912.09064, 2019.
以降の図はこの論文の著者のチームの研究者のカンファレンスのスライド(前掲のLujo Bauerのスライド)から引用しています。図5は敵対的サンプル生成のイメージです。
図 5: マルウェア検知を回避する敵対的サンプルの生成イメージ
出所:次のスライドを元に作成。Lujo Bauer, “On the Susceptibility to Adversarial Examples Under Real-World Constraints,” SlidesLive, Apr 26, 2020.
ここでは、「元の機能は変更しない」「機能に影響しない領域をランダムに変更させるという手法は利用しない(成功率が低いため)」という制約を課して、以下の手順で生成しています。
- バイナリの命令コードを、機能を変えないようにしながら順番を変更
- 変更したものをマルウェア検知モデルに入力し、マルウェアと判断されるスコアが下がればまた少し順番を変更
- マルウェアではないと誤分類されるまで繰り返し
「VirusTotal」というマルウェア検査を行うウェブサイト経由で68種類のマルウェア検知ソフトを用いて試したところ、平均して50パーセント程度の精度で回避できたという研究成果が出ています。
- VirusTotalhttps://www.virustotal.com/gui/
昨今、マルウェアによる被害が相次ぐ中、マルウェア検知を回避する敵対的サンプルはダイレクトにセキュリティの脅威となり得ます。
音声の敵対的サンプル
昨今、Apple Siri、Amazon Echo、Googleアシスタントなどに代表される音声認識にはDNNが利用されています。通常、音声認識は、音声を認識してそれをテキストに変換します。この領域でも敵対的サンプルの研究は行われており、オリジナル音声の本来の意味とは異なるフレーズとして認識させることに成功している研究があります。
N. Carlini and D. Wagner, “Audio Adversarial Examples: Targeted Attacks on Speech-to-Text," 2018 IEEE Security and Privacy Workshops, 2018.
音声認識での敵対的サンプルによる攻撃はオリジナルの音声波形にノイズとして別の音声波形を加えることで、別のフレーズに認識させることです(下図)。

図 6: 音声認識での敵対的サンプルのイメージ
出所: N. Carlini and D. Wagner, “Audio Adversarial Examples: Targeted Attacks on Speech-to-Text," 2018 IEEE Security and Privacy Workshops, 2018.
https://arxiv.org/abs/1801.01944
この研究の優れている点は、オリジナル音声と同じように聞こえるにもかかわらず、「任意」のフレーズとして誤認識させることができる点です。次の「Audio Adversarial Examples」は、上記の論文の著者が公開しているデモサイトです。Mozillaが開発している、DeepSpeechという音声認識モデルに対する複数の攻撃デモが公開されています。
Audio Adversarial Examples
https://nicholas.carlini.com/code/audio_adversarial_examples
わかりやすい脅威例として、オリジナルの音声が「without the dataset the article is useless」の音声を「okay google browse to evil dot com」と誤認識させることに成功しているデモがあります。
これは、攻撃者がターゲットのGoogleアシスタントを起動して強制的に悪意のあるサイトに誘導できることを示唆しています。もちろん、なんらかの方法で敵対的サンプルを再生させる、もしくは音声を拾わせるといった受動的攻撃が前提となると、攻撃難易度は高いですが、音声認識に依存している機能に対して任意の操作を攻撃者に許してしまう危険性があります。
ディープフェイクとその検知の回避
ディープフェイクとは、AIを使って作り出される偽の情報です。一口にディープフェイクと言っても定義が難しいですが、ここでは、“AIを使って作り出された本物に似せた何か”と考えていただくとよいでしょうか。
なかでも昨今は、ディープラーニングを応用した顔合成技術を使って有名女優のフェイクポルノを生成したり、著名人があたかも登場しているかのような動画を生成したりして偽の情報を流すといった問題が話題になっています。
たとえば、2019年にはFacebook CEOであるマーク・ザッカーバーグ氏が、「人々のデータを1人の男がコントロールすることを想像してください」と訴える様子がディープフェイクの動画で生成され話題となりました。
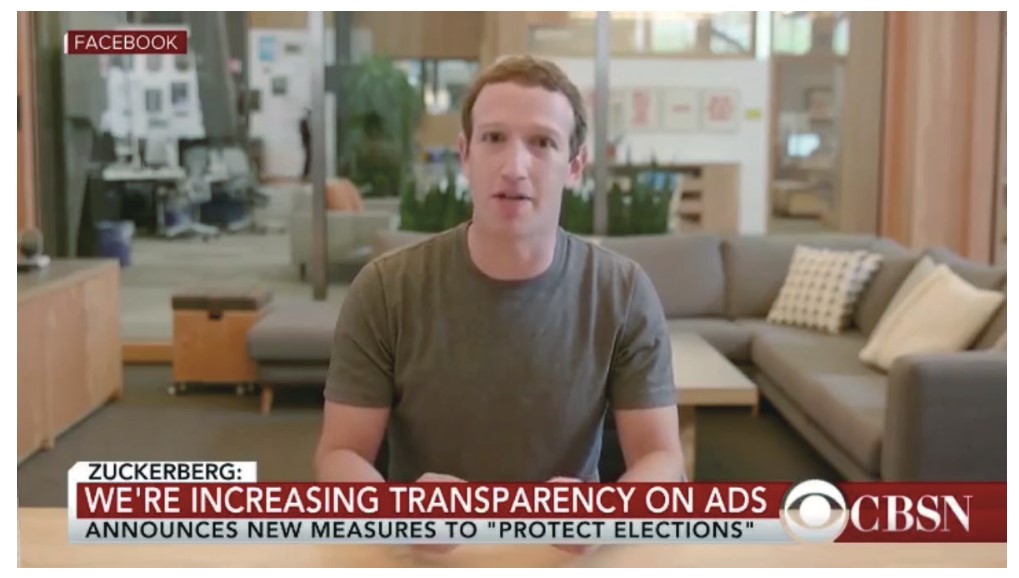
図 7: Facebookのマーク・ザッカーバーグCEOのディープフェイクのニュース
この動画は以下のURLで閲覧可能です。
Instagramでシェアされたマーク・ザッカーバーグCEOのディープフェイク動画(アクセス日時:2020年11月21日16時26分)https://www.instagram.com/p/ByaVigGFP2U/
見た目は、明らかにマーク・ザッカーバーグCEOで、多少の不自然さは人によって感じるかもしれませんが、かなり自然な動画です。ディープフェイクと知らずに見ると本物のマーク・ザッカーバーグCEO と勘違いする可能性は高いと思います。マーク・ザッカーバーグCEOの例は実在する人物へのいわば「なりすまし」のような例ですが、実在しない人物をリアルなイメージで合成することも可能です。
たとえば、存在しない画像でSNSのアカウントを登録するといったことも可能になります。図8は、アンドリュー・ウォルツという名前の人物で、この人物のTwitterアカウントとウェブページによると、ロードアイランド州の議会の議席に立候補していたとされています。
しかし現実には、ウォルツ氏は存在せず、17歳の高校生がディープラーニングを利用して生成したディープフェイクです。この画像は「StyleGAN2」と呼ばれるモデルによって生成されています。

図 8: 17歳の高校生によって生成されたディープフェイク。アンドリュー・ウォルツという名前となっているが実在しない
Facebookは今や社会に大きな影響力を持っています。このような大企業のCEOのディープフェイクが偽の情報を発信したらどうなるでしょうか?
たとえば、Facebookサービスへの特定国家からのアクセス停止宣言、個人情報漏洩の報告、他社の買収話などの偽情報は、株価に大きな影響を与える可能性も考えられます(あくまで例です)。また、アンドリュー・ウォルツのような実在しない人物とはいえ、政治家というだけで影響力は高く、世論を操作できてしまう可能性だってあるのです。
これらの例に留まらず、ディープフェイクの悪用はインターネットが普及した今日、非常にリスクが高いことは容易に想像できると思います。ディープラーニングは本来、人類のための技術であるべきなのに、残念なことに人類の脅威も作り出すのです。
このような懸念から、ディープフェイクであることを見抜く(検知する)ためのDNNの研究も活発に行われています。同時に、残念ながらそれらを回避するための敵対的サンプルの脅威も存在します。図9は、ディープフェイクの検知を回避し、本物と誤分類させる手法を解説した論文からの引用です。
図 9: ディープフェイクのアンドリュー・ウォルツ氏の敵対的サンプルを生成し、ディープフェイクの検知モデルを回避
出所:N. Carlini and H. Farid, “Evading Deepfake-Image Detectors with White- and Black-Box Attacks,” 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, IEEE, 2020.
https://arxiv.org/abs/2004.00622
真ん中の(b)のディープフェイク写真に(c)を1000で割ったものをノイズとして加え、敵対的サンプル(a)の画像を生成しています。この敵対的サンプルは既存のディープフェイク検知モデルが99パーセントのスコアで「本物」と誤分類した例です。
この例が示すように、ディープフェイクを検知する防御とそれを回避する攻撃はイタチゴッコになることが予想できます。脅威レベルは高く、かつ防御の難易度も高いという、人類が直面する最も頭の痛い問題の1つになるであろうと筆者は考えます。
まとめ
本稿では複数の研究事例を紹介しましたが、「今利用しているAIが簡単に騙されたらどんな脅威となるか?」という視点を持っていただくと、敵対的サンプルは我々にとって身近な脅威となる可能性があるということがよりご理解いただけるのではないかと思います。
セキュリティの文脈での AI はこれまで、セキュリティ対策のためにどのように AI を『活用』するか?に注目が集まっていましたが、『AI そのもの』のセキュリティに対してもますます注目が集まってくることでしょう。本稿が、インターネットセキュリティならぬ次世代セキュリティであるAIセキュリティの「対話を始めるスタート」となれば幸いです。
本稿では敵対的サンプルの仕組みの解説は概要レベルにとどめましたが、次回以降でどのようにして敵対的サンプルを生成するかについて「攻撃者の視点」で解説し、その上で、攻撃に対する頑健性をどのようにして向上させるかについて、つまり防御の話も取り上げます。
前述した通り、敵対的サンプルは数学を根拠に計算して作られ、そこにはサイエンスがあります。筆者自身、このサイエンスに基づいた攻撃および防御の考え方を理論レベルで理解したときには、胸が高鳴ったのを覚えています。AIセキュリティというのは、それ自体が「学ぶに値する面白さに満ちている」という点は筆者が約束しますのでご期待ください。
なお、本稿の説明は拙著「AIセキュリティから学ぶ ディープラーニング[技術]入門」をベースにしています。より詳細をご覧になりたい方は、是非書籍もご覧ください。
本ブログの執筆者が所属する研究チーム紹介ページはこちら!

















