




はじめに
オンプレミスだけのシステムを利用していた企業が、自社の情報システムやお客様向けの提供システムをクラウドマイグレーションする事例をよく耳にします。クラウドマイグレーション後のシステムの監視設計・運用設計、できていますか?特にシステムモニタリングやセキュリティモニタリングを、旧来のモニタリングツールのみで行おうとしている方は、その考え方をアップデートしてみませんか。

モニタリングと課題
クラウド、コンテナ、サーバーレス、Infrastructure as Codeといったプラットフォーム技術の変革と、CI/CD、DevOps、Agileといったアプリケーション開発技術の変革に伴い、ソフトウェアアーキテクチャもモノリスからマイクロサービスへと変化しつつあります。
モニタリングについてはいかがでしょうか?改めて考えていただきたいのは、モニタリングの目的は何かということです。一般的には、アプリケーションの正常性確認、トラブルの原因調査、キャパシティの分析、ユーザー行動の分析、経営判断指標などが挙げられます。
旧来のpingを用いた死活監視やSNMPを用いたリソース監視だけでは、Twitter社のような大規模分散システム[1]のサービスモニタリングを行うことが難しいのは自明でしょう。大規模システムやマイクロサービスにおいてはホスト単位の監視だけにとどまらず、サービスのパフォーマンスやスケーラビリティ、信頼性までを含めたサービスベースでのモニタリングが求められます。
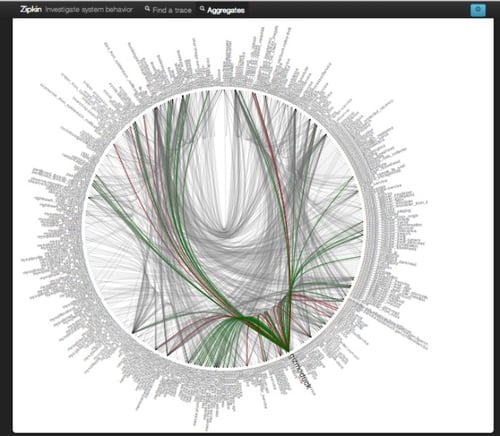
図1:Twitterの分散アーキテクチャ
オブザーバビリティ
ここでオブザーバビリティという新しいモニタリングの概念について紹介したいと思います。モニタリングは事前に定義した設定のもと、異常が見つかるとアラートとして通知するものであり、オンコール対応やインシデント対応のトリガとなります。
オブザーバビリティは「可観測性」とも訳される通り、システム内部の状態をどれだけよく理解できるかを測定するものであり、モニタリングを支援します。複雑なマイクロサービスアーキテクチャに対して、監視の事前定義が困難であっても、その影響と原因がどのような状態であるかをリアルタイムに確認することができます。
オブザーバビリティの実現のためには、「メトリクス」、「ログ」、「トレース」というデータタイプを収集、分析、可視化する必要があります。これらのデータタイプを総じて「テレメトリーデータ」あるいは単純に「テレメトリー」と呼びます。
テレメトリーデータについてもう少し詳しく説明します。「メトリクス」は実はこれまでの運用担当者にとっては馴染みのあるもので、定期的にシステムのヘルス情報やパフォーマンス情報を取得し、測定値をグループ化したものです。たとえば、CPU使用率、メモリ使用率、ディスク使用率、Data I/O、アクセス数などがこれにあたります。
「ログ」は運用担当者だけでなく開発者にとっても馴染みのあるもので、コンポーネントが特定のタイミングでの処理内容に関する情報を記録したテキストデータです。ログはメトリクスよりもより詳細な情報を提供してくれますし、改ざんされていないことが担保できれば監査のための材料にもなります。
大容量になりがちなためにログ保存にかかるコストが高かったり、機器やサービスによってログ形式が異なるために必要な箇所を抽出する前処理が大変だったりと欠点はありますが、ログの一行は血の一滴といわれるくらい、とても重要なものです。
「トレース」はこれまでの運用担当者にも開発者にも馴染みのない言葉かもしれません。これはマイクロサービス間や異なるコンポーネント間のイベントの因果連鎖を追跡するものです。ログのようなコンポーネント単位ではなく、システムへのリクエストのライフサイクルを横断して見ることがトレースという概念です。
トレースを活用すると、サービスマップを表示してアプリケーション内のサービスおよびリソースの関係を可視化し、数クリックするだけで不具合の箇所を迅速に特定できるようになります。オブザーバビリティサービスによっては、クラウドサービスのコンポーネントだけでなく、オンプレミスのネットワークデバイスやサーバなども一つのコンポーネントと捉え、トレースの対象と見なすことができます。
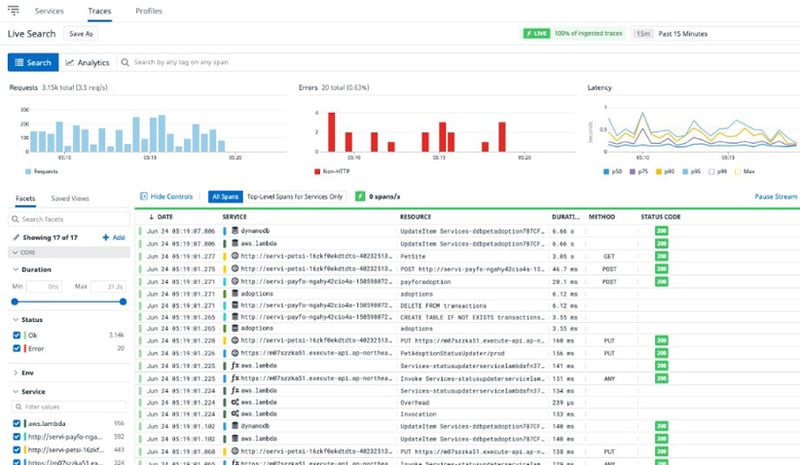
図2:Datadogを使ったトレースのダッシュボード
近年、このようなオブザーバビリティを実現するサービスは、Amazon Web Services(以下、AWS)をはじめ、多くのクラウドサービスにおいても提供されています。サードパーティのオブザーバビリティサービスですと、Datadog[2]、New Relic[3]、Dynatrace[4]、Splunk[5]などが代表的です。
AWSにおけるモニタリング・オブザーバビリティ
実際に旧来のモニタリングから発展を遂げた現在のモニタリング・オブザーバビリティについて、どのようなことができるのか、AWSが提供するサービスを例にいくつか取り上げてみたいと思います。AWSでは、2009年に発表されたAmazon CloudWatch[6](以下、CloudWatch)、2016年に発表されたAWS X-Ray[7](以下、X-Ray)がモニタリング・オブザーバビリティを代表するサービスになります。それぞれのサービスも日に日に進化を遂げてきましたが、特にCloudWatchについては目を見張るものがあります。
また、今回は触れませんが、他に2020年に発表されたAmazon Managed Service for Prometheus[8] および Amazon Managed Grafana[9]、2021年に発表されたAWS Distro for OpenTelemetry[10]も存在します。興味をお持ちの方は脚注・参考をご確認ください。
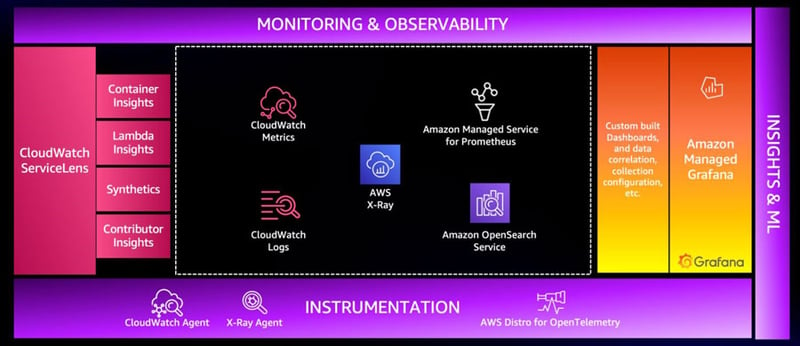 図3:AWSのモニタリング・オブザーバビリティ
図3:AWSのモニタリング・オブザーバビリティ
AWSでは、One Observability Workshop[11]というワークショップが公開されており、AWSアカウントをお持ちの方なら誰でもAWSにおけるモニタリング・オブザーバビリティを学ぶことができます。こちらではマイクロサービスを活用してペットショップサイトを構築し、ハンズオン形式でモニタリング・オブザーバビリティの活用方法を体感することができます。こちらを題材に、AWSが提供しているモニタリング・オブザーバビリティ関連のサービスを11種類ご紹介します。
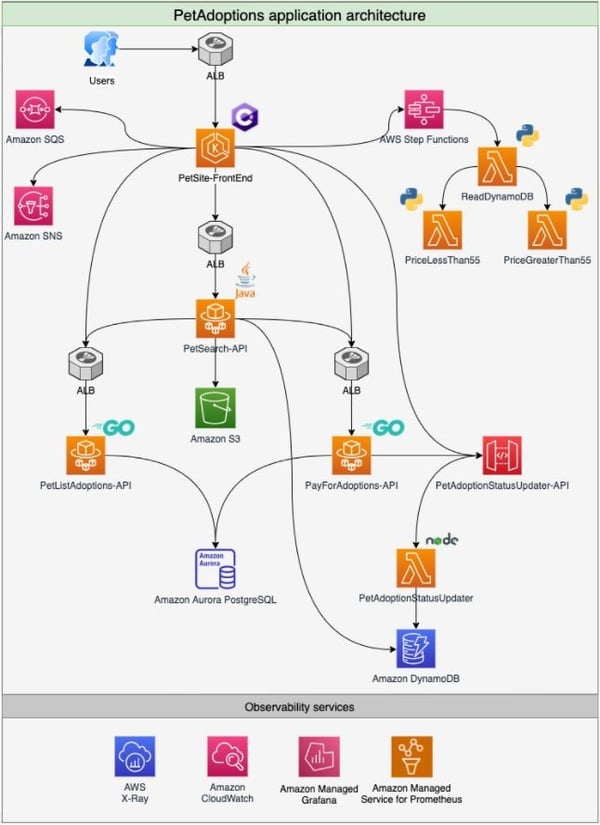
図4:ワークショップ環境のアーキテクチャ
図5:デモサイト
1.CloudWatch Metrics/Dashboard
種々の監視メトリクスデータを取得・蓄積し、グラフ化して表示することのできるサービスです。下記はAmazon Elastic Load Balancing[12](以下、ELB)というロードバランササービスのアクティブコネクション数の合計をメトリクスとして取得し、時系列で表したグラフになります。
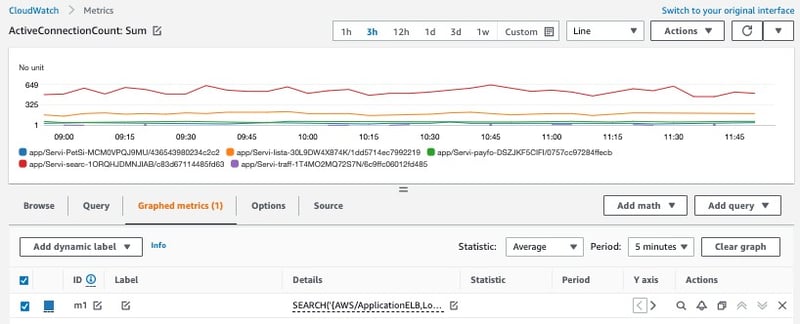
図6:CloudWatch Metrics
2.CloudWatch Alarm
CloudWatchに蓄積されたデータをもとに閾値ベースでの監視を行い、アラートを発報するサービスになります。アラートはAmazon Simple Notification Service(以下、SNS)という通知サービスを通じて通知を行ったり、チケット管理のサービスに自動連係したり、オンコールサービスに連携することが可能です。
下記はAmazon DynamoDB[13](以下、DynamoDB)というデータベースサービスの書き込みスロットリングに関するアラート設定を示したグラフです。アラームイベントが発生していないため、正常稼働状態であることがわかります。
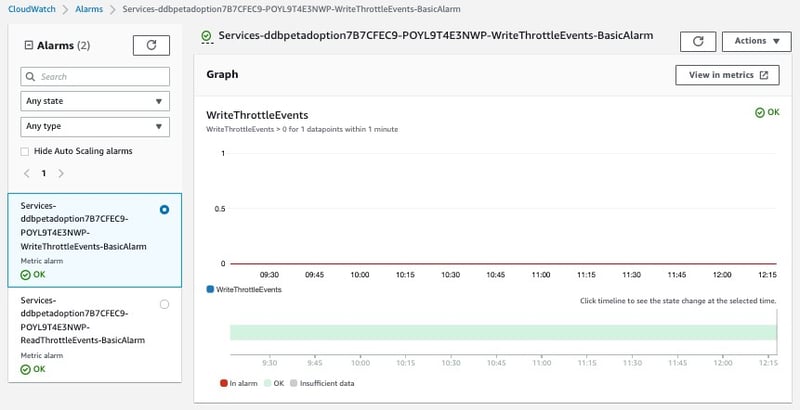
図7:CloudWatch Alarm
3.Amazon X-Ray
特定のアプリケーションを通過する際のリクエストのエンドツーエンドな通信の詳細をビューで確認することができるサービスです。アプリケーションとプラットフォームサービスがどのように実行されているかを理解し、エラーの根本原因を特定することで、アプリケーションのパフォーマンス問題の解消に生かすことができます。この種のモニタリングをアプリケーションパフォーマンスモニタリング(Application Performance Monitoring;APM)と呼びます。
たとえば、図のようにフロントサイトのサービスを選択し、レスポンスタイムの分布図を見ると、一定割合のWeb応答が遅い事象が発生していることを見つけることができます。こうした問題を認知し、より深堀をしていくきっかけを与えてくれるのがX-rayを始めとするAPMです。
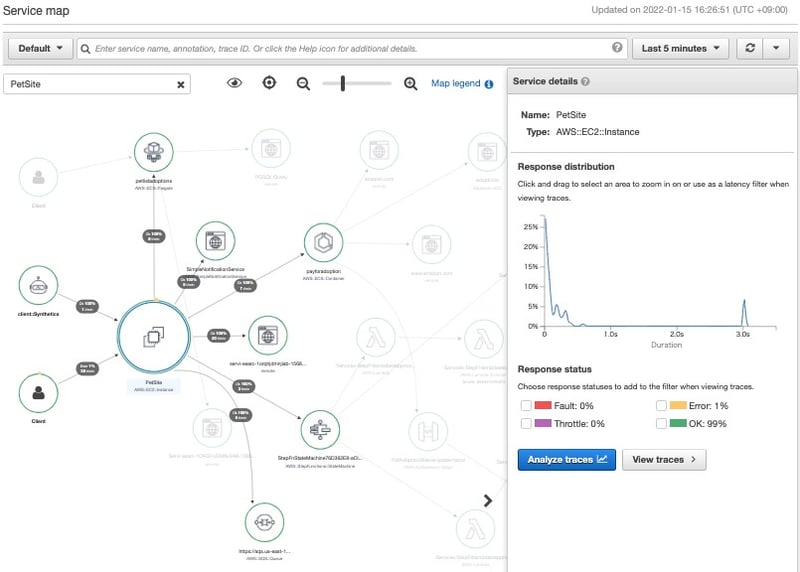
図8:X-Ray
4.Amazon CloudWatch Anomaly Detection
CloudWatchのメトリクスの過去データをもとに機械学習ベースでの外れ値検知をするサービスであり、従来の固定閾値ベースよりも柔軟な監視が可能です。
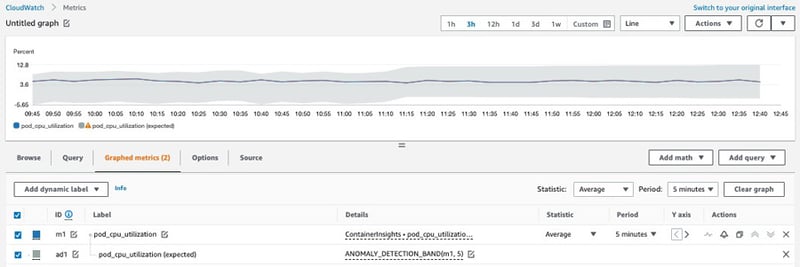
図9:Anomaly Detection
5.Amazon CloudWatch ServiceLens
メトリクス、ログ、トレースの各種テレメトリーデータとアラームを1か所に集約するサービスです。パフォーマンスモニタリングによるボトルネックや異常を効率的に特定し、影響を受けたユーザーを特定するのに役立ちます。CloudWatchとX-Rayが統合されており、トラフィック遅延やエラーなども強調して表示することができるため、テレメトリーデータとの相関関係を詳細に表示することも可能となります。
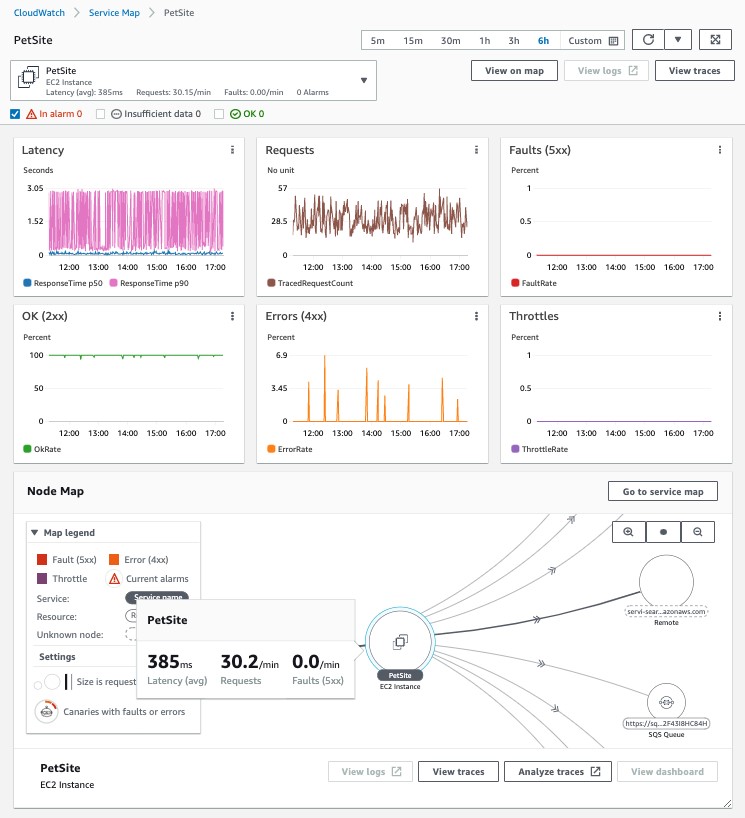
図10:CloudWatch ServiceLens
6.Amazon CloudWatch Contributor Insights
時系列データを分析して、システムパフォーマンスに影響を与えているトップコントリビューターのビューを確認することができるサービスです。たとえば、特定のDynamoDBにてどのペット関連のものに対するアクセスが多い(コントリビュートしている)のかを可視化することができます。また、閾値アラートを設定することも可能です。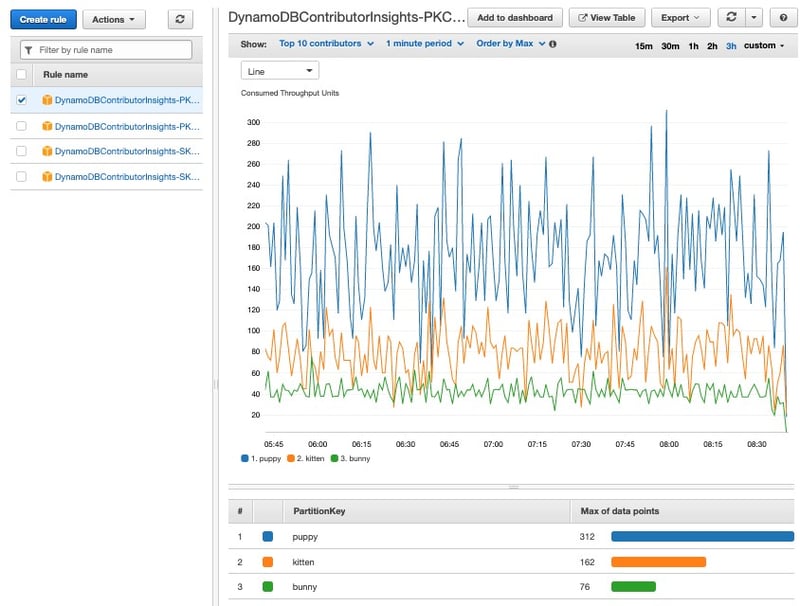
図11:CloudWatch Contributor Insights
7.Amazon CloudWatch Synthetics
エンドポイントとAPIを監視するためのカナリア(スケジュールに従って実行される設定可能なスクリプト)を作成し、顧客と同じルートを辿ったアクセスやアクションを実行するサービスです。旧来のURL監視をより発展させたものと考えるとよいでしょう。自動でサイトアクセス時のスクリーンショットの取得をすることができます。
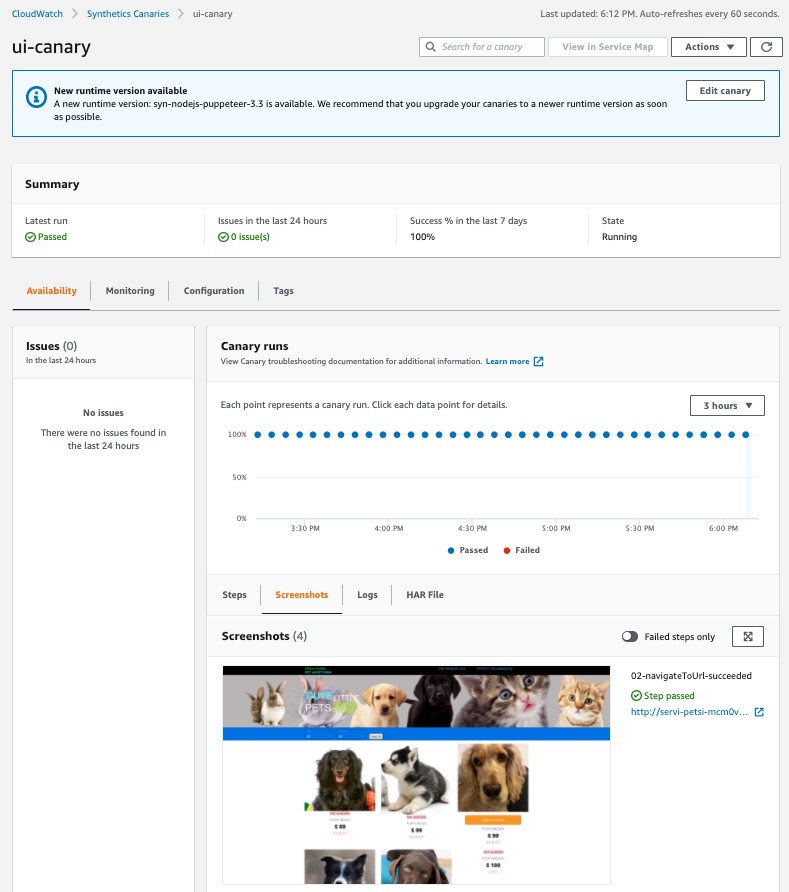
図12:CloudWatch Synthetics
8.Amazon CloudWatch RUM(Real User Monitoring)
Webアプリケーションのパフォーマンスに関するクライアント側のデータをリアルタイムで収集し、ユーザーモニタリング結果を提供するサービスです。デバイス情報やアクセス元ロケーションの情報、レイテンシーなどを理解することができます。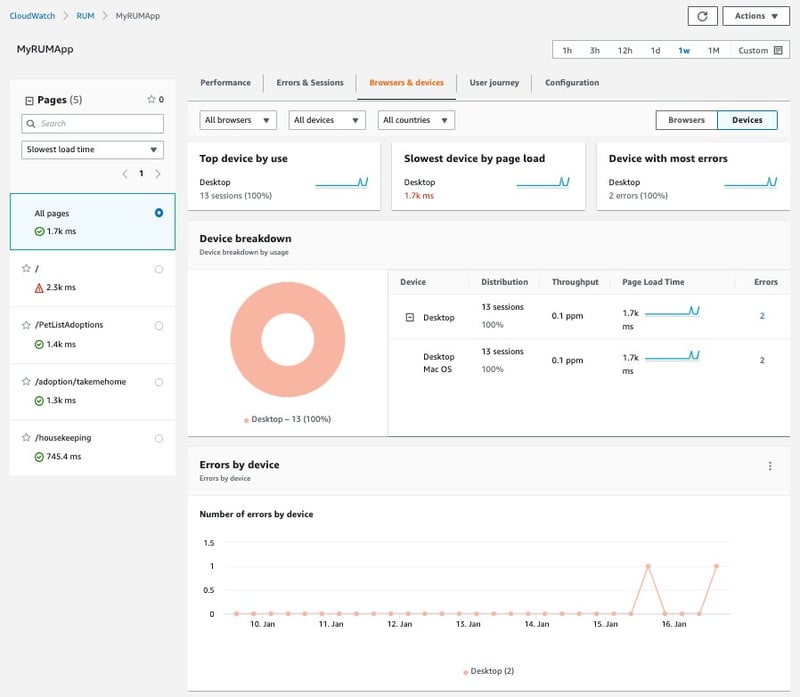
図13:CloudWatch RUM
9.Amazon CloudWatch Container Insights
コンテナ化されたアプリケーションとマイクロサービスからメトリクスとログを収集、集約、要約するサービスです。複数のマネージドコンテナサービスもサポートしています。普遍的なメトリクス情報も取得されますが、コンテナの再起動の失敗などの診断情報も提供し、問題を切り分けて迅速に解決するのに役立ちます。
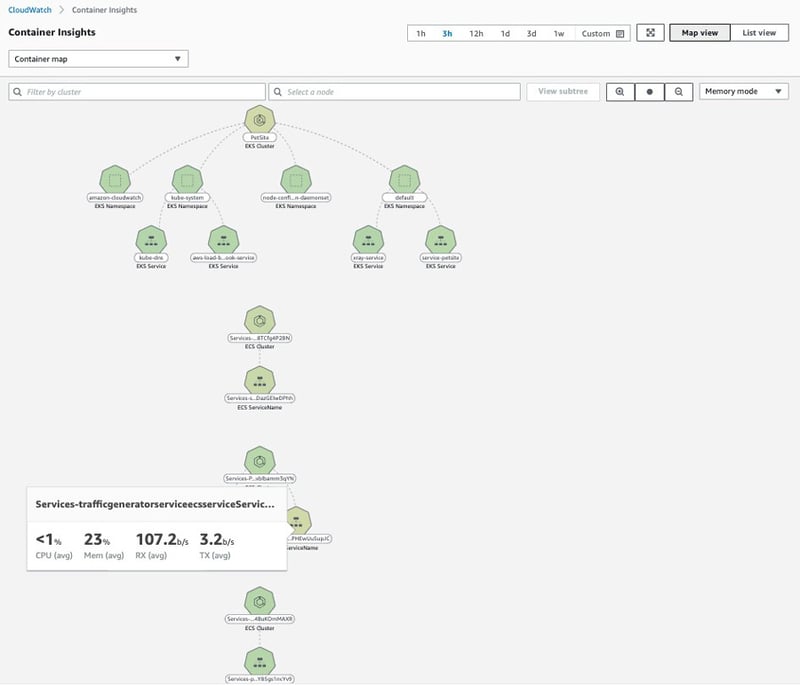
図14:CloudWatch Container Insights
10.Amazon CloudWatch Logs Insights
CloudWatch Logsのログデータを簡単に検索、分析することができるサービスです。問題が発生した際の調査に役立てることができます。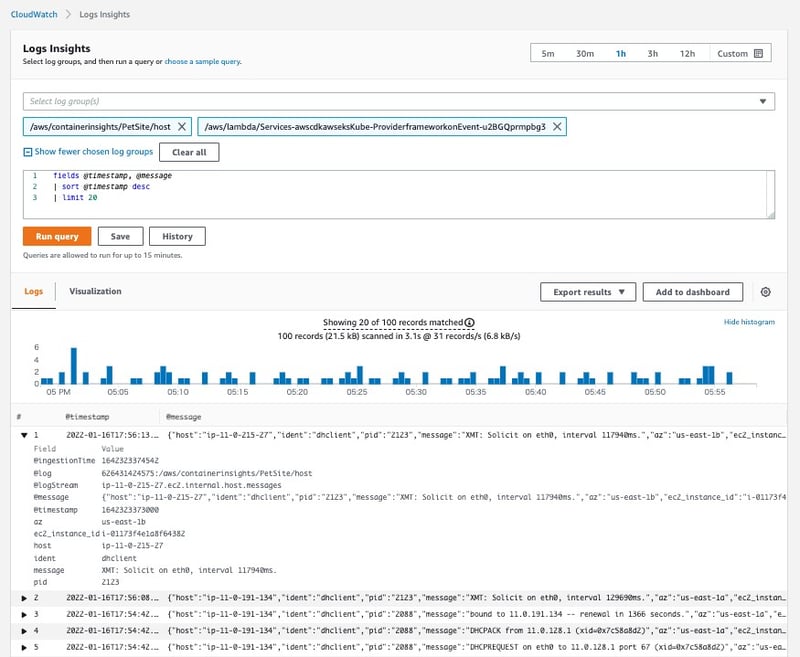
図15:CloudWatch Logs Insights
11.Amazon CloudWatch Lambda Insights
AWS Lambda[14](以下、Lambda)で実行されるサーバーレスアプリケーションのモニタリングやトラブルシューティングを行うサービスです。Lambda実行における診断情報を集め、問題の切り分けに利用することができます。
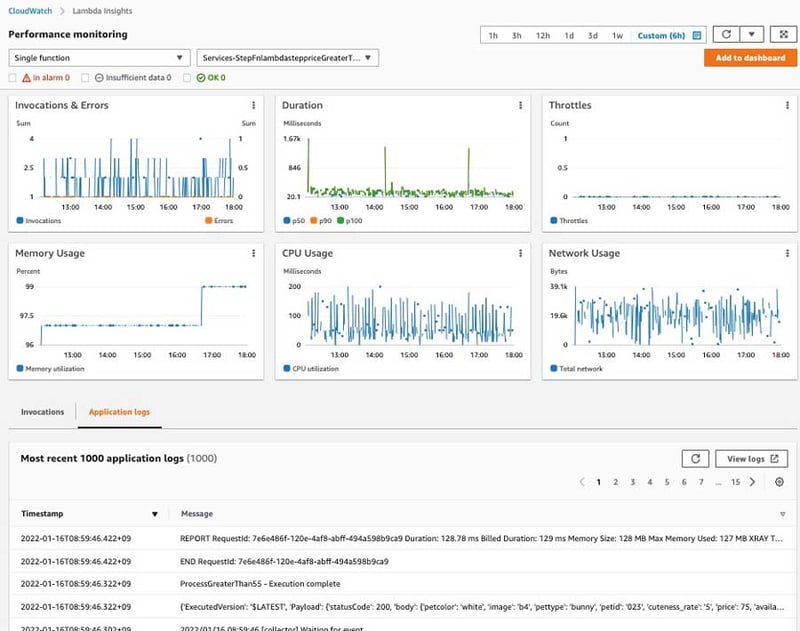
図16:CloudWatch Lambda Insights
以上11点が、AWSが提供しているモニタリング・オブザーバビリティの機能についての紹介でした。
おわりに
AWSを題材に、モニタリング・オブザーバビリティの紹介をしました。モニタリングもオブザーバビリティも、取り組み方次第では、多くの企業にとって、ビジネスをより良くドライブできる武器となり得ます。改めてモニタリングの目的は何か?ということを今一度お考えいただき、その目的が達成できるようなモニタリング・オブザーバビリティが実現できることを願っています。
脚注・参考
|
Observability at Twitter https://blog.twitter.com/engineering/en_us/a/2013/observability-at-twitter |
|
|
Datadog |
|
|
New Relic |
|
|
Dynatrace |
|
|
Amazon CloudWatch |
|
|
AWS X-Ray |
|
|
Amazon Managed Service for Prometheus |
|
|
Amazon Managed Grafana |
|
|
AWS Distro for OpenTelemetry |
|
|
One Observability Workshop |
|
|
Amazon Elastic Load Balancing |
|
|
Amazon DynamoDB |
|
|
AWS Lambda |





















